Deep Learning Frameworks
By Adson Nogueira Alves
Introdução as Ferramentas de Aprendizado de Máquina
 Fonte: Pixabay
Fonte: Pixabay
Visão Geral
Quando falamos de Inteligência Artificial (IA) ou Aprendizado de Máquina, logo vem à mente algo extremente complexo e que seriam necessários anos de estudo e dedicação para um total entendimento da área, não é mesmo ?
Você está correto!😲🤯
😂😂😅 É brincadeira, não se desespere!
Este material tem como objetivo apresentar uma introdução a Frameworks frequentemente utilizadas no aprendizado de máquina.
Não se preocupe se esse for o seu primeiro contato com o tema de Inteligência Artificial, faremos uma fundamentação téorica básica sobre o tema antes de chegar nas ferramentas.😉
O que é Inteligência Artificial ?
Uma das definições possiveis para Inteligência Artificial (IA), segundo Raymond Kurzweil, é dizer que:
‘É a arte de criar máquinas que desempenham funções que requer inteligência quando desempenhadas por pessoas’.
Logo, podemos dizer que são algoritmos que imitam a inteligência humana, se tornando habilidosos na resolução de problemas da forma que consideramos inteligente. Podendo ser um algoritmo simples ou complexo.
Certamente, você também já se deparou com o termo Aprendizado de Máquina ou Machine Learning, considerado uma subárea de IA. Podemos pensar na seguinte definição.
Algoritmo que analisa dados, aprende a partir deles e então utiliza o que aprendeu para tomar decisões em um novo conjunto de dados. Utilizando caracteristicas extraidas desta base e melhorando a robustez do modelo de IA a partir da experiência.
Temos ainda o termo Aprendizado Profundo ou Deep Learning que por sua vez é uma subárea de Machine Learning.
Podemos definir assim:
Algoritmo de rede neural que aprende caracteristicas importantes nos dados intrinsecamente. Adaptando-se a partir de repetidos treinamentos, descobrindo novos padrões e percepções.
Aprendizado Supervisionado e Não Supervisionado
Existem alguns tipos de aprendizado de máquina, neste material vamos definir o Aprendizado Supervisionado e o Não Supervisionado.
Sendo:
-
Aprendizado Supervisionado: nesta abordagem temos bem definido o alinhamento dos dados brutos com o rótulo, ou seja, sabemos de antemão a informação que queremos predizer. Um exemplo de aplicação seria criar um modelo que prevê a falha de algum componente baseado em parâmetros como: a velocidade, a aceleração e o torque, logo ter um alinhamento desses parâmetros com a ocorrência de falha é uma ação necessária. Dizemos que neste tipo de abordagem temos um agente “Professor” auxiliando o aprendizado.
-
Aprendizado não supervisionado por sua vez, não tem mais o agente Professor, teriamos apenas os dados de velocidade, aceleração e torque.
💡 Para cada tipo de aprendizado temos uma abordagem mais adequada.
Redes Neurais
Alguns modelos de aprendizado de máquina seguem uma arquitetura inspirada na representação do cérebro humano, chamamos de Redes Neurais Artificiais (RNA). Não é nosso objetivo explicar o funcionamento biológico dos neurônios, mas sim trazer suas inspirações ao cenário da Inteligência Artificial.
Os neurônios quando interligados, tem como objetivo transmitir uma informação ao subsequente gerando um determinado comportamento biológico, a imagem abaixo apresenta essa representação.
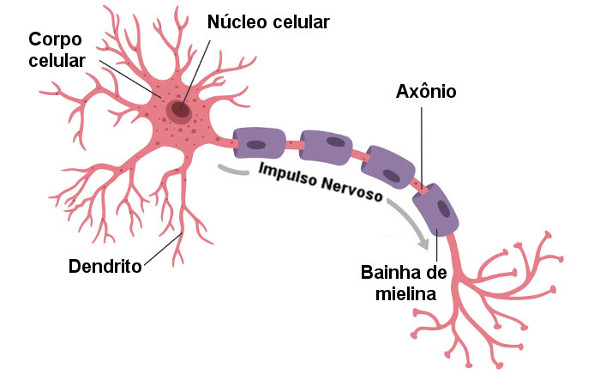 Fonte: Mundoeducacao
Fonte: Mundoeducacao
Em Redes Neurais Artificiais buscamos imitar esse comportamento aplicando uma analogia a esse modelo. Dessa forma, as entradas da RNA (similar aos dendritos), quando estimuladas, transmitem uma determinada informação (similar aos axônios), ponderando o dado. O objetivo é determinar um estado de saída que melhor atenda o propósito da aplicação. Como exemplo, quando se é estimulado o estado de dor, esperamos um comportamento de fulga ou outro mais adequado.
Um modelo matemático da representação do modelo, pode ser vista na figura abaixo, onde as entradas do neurônio são representadas pelo valor [x1…xm], na sequência as entradas são ponderadas com pesos [ωk1…ωkn], aplicando ao final um somatório destas informações. É apresentado um bias, junto ao somatório, que pode ser entendido como um comportamento proposital para convergência do modelo. Na sequência é aplicada uma função de transferência, responsável por transmitir esses dados ao próximo neurônio ou gerar a informação de saída (y).
 Fonte: Urantiagaia
Fonte: Urantiagaia
Dessa forma, a junção de vários desses neurônios é o que chamamos de Rede Neural Artificial 😃.
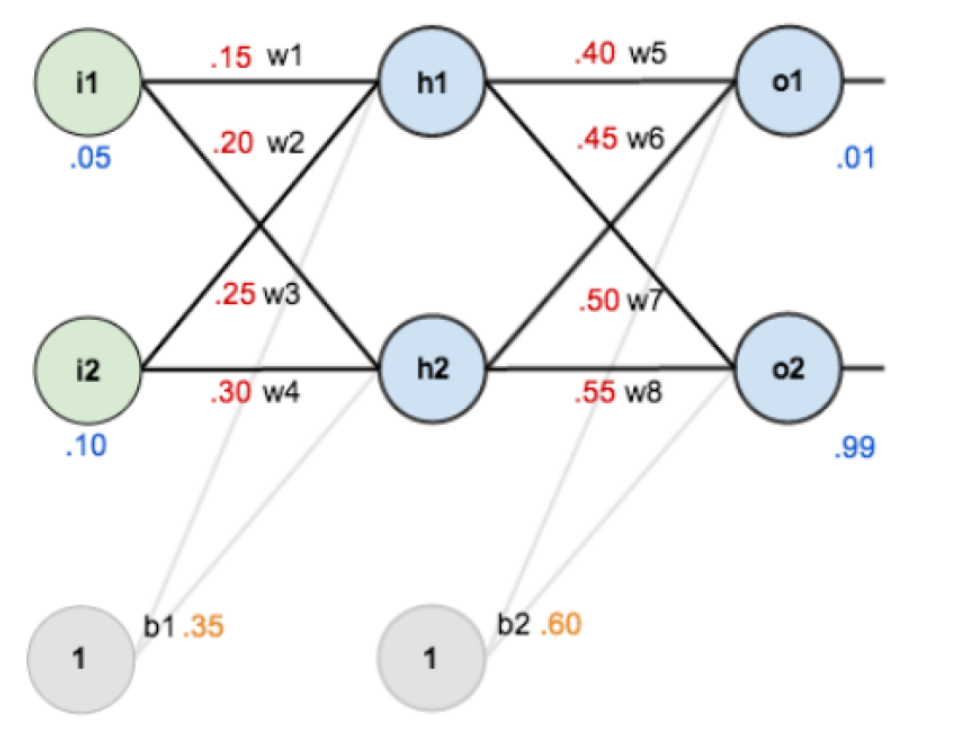
Na imagem abaixo você tem um exemplo de uma RNA simples, nela temos 3 camadas:
- A primeira chamamos de camada de entrada (com 2 dois neurônios - { i1 e i2 }
- A última é chamada de camada de saída (com 2 dois neurônios - { O1 e O2}
- Todas as camadas que estiverem entre a camada de entrada e a camada de saída é chamada de camada oculta
Não se preocupe com os valores associados aos neurônios eles serão discutidos futuramente.
Note que o todos os neurônios de uma camada estão conectados aos neurônios da camada anterior isso chamamos de camada densa, comumente usadas em RNA’s. As conexões entre os neurônios são feitas através de links, com um valor de peso associado [ω1…ωn].
Os Bias [b1, b2], que como dito anteriormente, é um estimulo proposital que faz com que o modelo convirja para o estado esperado. Ele é representado como um novo neurônio, existente para todas as camadas ocultas e a camada de saída, porém não precisa necessariamente conter o mesmo valor atribuído, podendo variar entre as camadas.
 Fonte: Medium
Fonte: Medium
Com essas definições, podemos agora discutir sobre o fluxo de trabalho de um projeto de Inteligência Artificial 🎉🥳.
Fluxo de trabalho
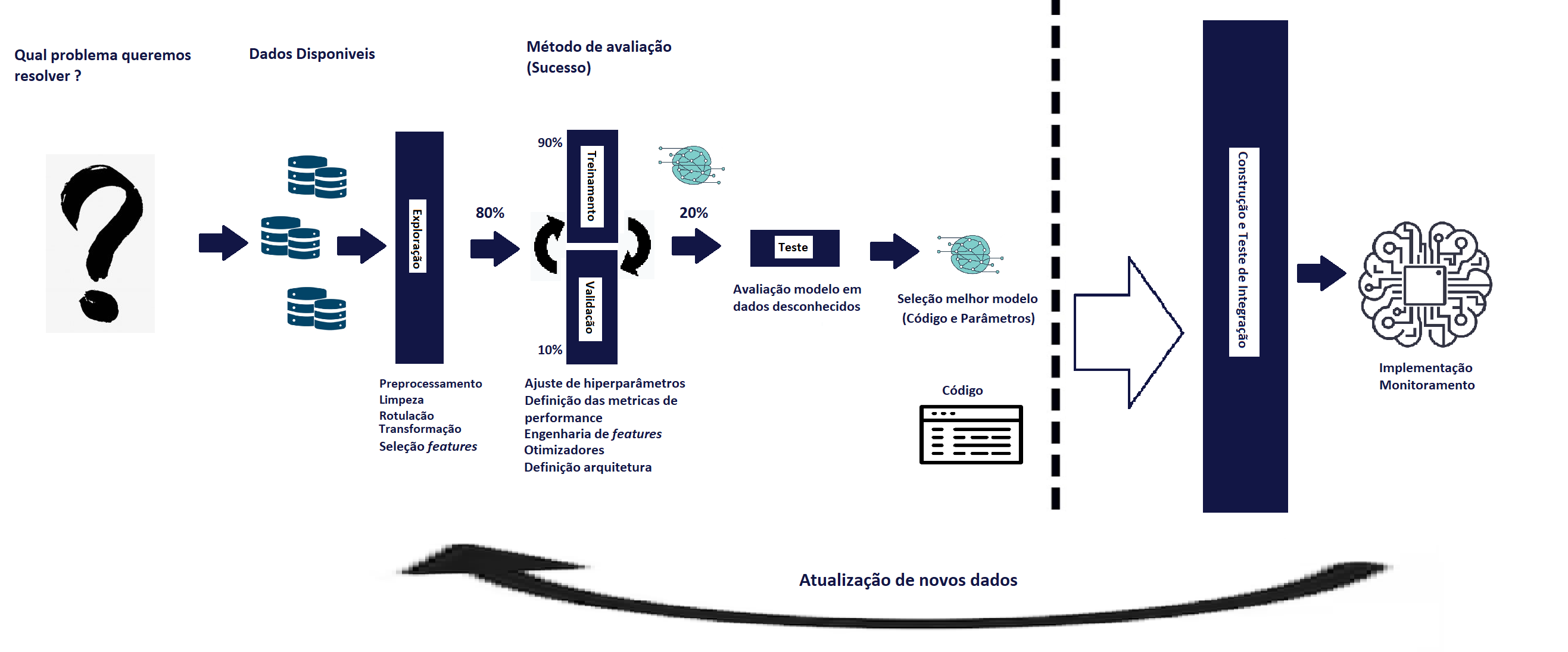
A Figura acima representa o fluxo de trabalho de um Projeto de IA 😜
-
É necessário ter bem claro o problema que queremos resolver, com isso será possivel definir quais dados serão mais relevantes para gerar um modelo de IA robusto.
-
Definido o problema e com clareza do objetivo do projeto, é hora de buscar base de dados, conhecidos como Datasets que representem bem o problema ao qual a análise será feita. Quão mais expecifico for o projeto, mais dificil será encontrar um Dataset adequado, neste caso, pode ser necessário gerar sua própria base de dados. Tenha bem definido tipo de aprendizado pretendido, com isso, será possível gerar a base de dados de forma adequada.
-
Agora é hora de explorar os dados 🔍, neste momento é importante realizar uma seleção de features, ou seja, a escolha de quais conjuntos de dados são mais relevantes para o projeto. Nesta etapa também fazemos a eliminação ou atualização de dados considerados fora de contexto ou fora do objetivo da aplicação. Técnicas de transformação como normalização, padronização, Análise de Componentes Principais (PCA), Análise Discriminante Linear (LDA), Análise de Componentes Independentes (ICA) poderam ser aplicadas.
-
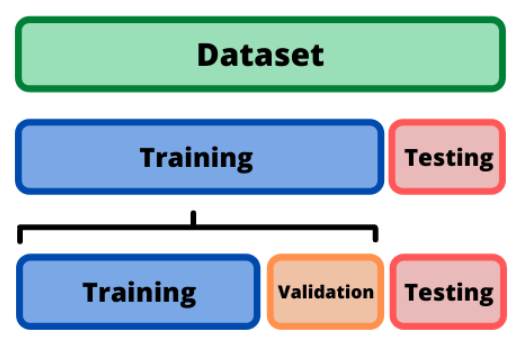
Agora faremos a separação dos dados entre dados de validação, treinamento e teste, uma etapa importante para robustez do modelo. Para explicar, vamos fazer uma analogia com o vestibular, nele investimos grande parte do nosso tempo estudando o conteúdo de várias matérias, normalmente reservamos o período de 1 ano para isso. Esta etapa representa o nosso TREINAMENTO, onde geramos conhecimento a partir dos dados. Continuando, durante o período de estudo podemos fazer simulados para validar o conhecimento aprendido e consertar o que não caminhou bem. Esta etapa é similar a nossa etapa de VALIDAÇÃO, onde validamos os conhecimentos aprendidos e fazemos ajustes caso necessário. Por último, no vestibular temos a prova oficial, obrigatoriamente uma prova inédita e sem consulta, utilizada para verificação do conhecimento. Esta etapa é similar a nossa etapa de TESTE, usado para determinar a robustez do modelo aprendido. Uma boa prática é separar 80% para o treinamento e validação e 20% para teste. Em treinamento e validação fazemos uma nova separação 90% - 10%, respectivamente.
Fonte: Analyticsindiamag
-
Então definimos a arquitetura de Rede Neural que será utilizada e a métrica de performance escolhida para o treinamento do modelo. Treinamos até atingir um nível satisfatório e realizamos ajustes, caso necessário, dos hiperparâmetros, métricas, otimizadores, etc.
-
Finalmente faremos o teste do modelo aprendido em dados desconhecidos, aqueles 20% separados anteriormente.
🚨 Importante: Utilize os dados de teste uma única vez para não gerar viês de modelo.
-
Realizamos então a escolha do melhor modelo 🥳 💻 (Código e parâmetros) encontrado durante os testes.
-
Como o projeto pode envolver a integração com outra aplicação, pode ser necessário realizar a contrução e testar.
-
Por fim é realizado o Deploy | Implementação e monitoramento da aplicação, podendo coletar novos dados para melhorar a performance do modelo. 🤓🙂💻🤩💪
Parabénsssss 🥳😻 ! Agora que você entendeu o básico sobre IA já podemos falar sobre as framewoks.

Fonte: Media.tenor.com
Fundamentação Teórica
Antes de conversar sobre as Frameworks vamos gerar uma fundamentação teórica de alguns conceitos importantes neste cenário.
Entendendo Module, Package, Library e Framework
As terminologias Module, Package, Library,Framework são usadas para descrever esquemas de classificação e reutilização de código. Apesar da definição depender do contexto e da linguagem de programação usada, lá vai uma definição para nossa aplicação:
- Module
O menor pedaço de software. Um módulo é uma coleção de métodos ou funções que estão prontos para serem usados em outro lugar, podendo ser importados para outros módulos.
- Package
Um conjunto de módulos; podendo ser usados para interagir com outros programas. Usado para organizar, compartilhar e manter o código de alto nível. Podendo incluir módulos e pacotes adicionais ou coleções de módulos relacionados.
- Library
Uma coleção de pacotes. Seu objetivo é oferecer uma coleção de recursos prontos para uso sem impor nenhum padrão de código.
- Framework
Uma coleção de padrões e bibliotecas para desenvolver um tipo específico de aplicação. Fornecendo um ponto de partida para o desenvolvimento, porém impõe padrões de design e princípios arquitetônicos específicos. Os frameworks especificam como o programa deve ser organizado, e o desenvolvedor é obrigado a aderir a essas restrições.
Frameworks
Podemos definir uma Framework como uma:
Coleção de funcionalidade para facilitar o desenvolvimento de soluções, tanto solução de inteligência artificial, machine learning ou deep learning. Podendo utilizar algoritmos e modelos que já foram implementados anteriormente.
Logo:
- Não precisamos reinventar a roda.
- Permite o foco no problema a ser resolvido ao invés de focar nos algoritmos e métodos que serão utilizados para solução do problema.
- Otimização das funcionalidades.
- Suporte da comunidade, tanto no desenvolvimento quanto na solução de problemas.
Imagem abaixo ilustra a relação do código, biblioteca e estrutura. 😉

Fonte: Medium
Existem algumas Frameworks disponíveis para Inteligência Artificial a imagem abaixo apresenta algumas opções.
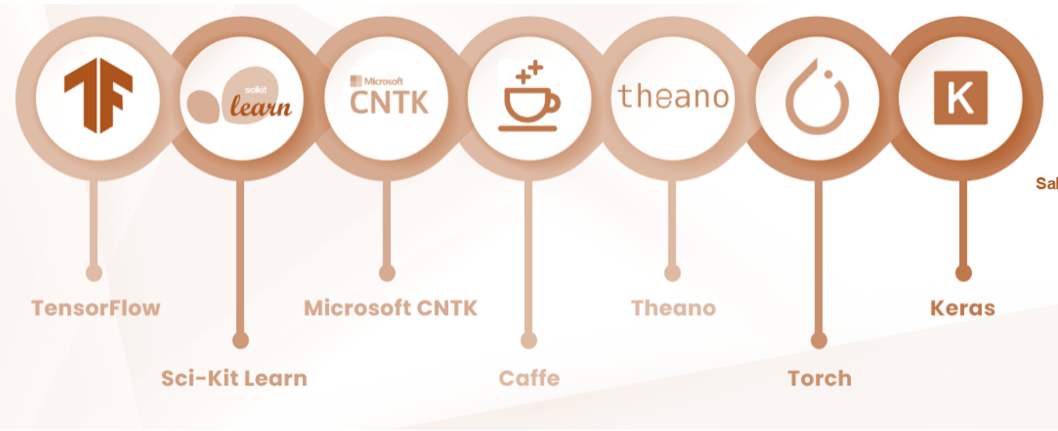
Fonte: Medium
Neste material utilizaremos o:
💡 Acesse a documentação das frameworks nos links acima.
Pytorch
No nosso primeiro exemplo utilizaremos o Pytorch que segundo a própria empresa é uma Framework open-source de aprendizado de máquina que acelera o caminho da prototipagem de pesquisa para a implantação da produção.
Passo 1 - Para utilizar a estrutura do pytorch é necessario importar o Pytorch , torch. Também vamos importar o pacote torchvision que consiste de Datasets populares, arquiteturas de modelo e transformações de imagem comuns para visão computacional.
import torch
import torchvision
Passo 2 - Nosso segundo passo serve para definir a GPU como dispositivo a ser utilizado para acelerar o treinamento.
Se utilizar o Colab, lembre de habilitar o dispositivo no notebook indo em Editar-> Configurações de Notebook -> Acelerador de Hardware e selecionar GPU
torch.device("cuda")Passo 3 - Em seguida vamos executar uma etapa de definição do pré processamento dos dados, para isso vamos utilização o método transforms para executar a normalização e a tranformação dos dados em tensores. Na normalização definimos uma média e desvio padrão de 0.5.
💡 Etapas de pré processamento de dados são realizados em IA afim de reduzir custos computacionais, viés de dados, balanceamento entre outros.
from torchvision import transforms
transformacao = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5))
])Passo 4 - Nossa próxima etapa é baixar o Dataset com os dados de treinamento e teste e aplicar o pré processamento criado.
Como exemplo utilizaremos o MNIST, que é uma base de dados de dígitos escritos manualmente, útil para treinar e testar o nosso modelo.
from torch.nn.modules import transformer
dataset_treino = torchvision.datasets.MNIST("./dados", download=True,train=True, transform=transformacao)
dataset_teste = torchvision.datasets.MNIST("./dados", download=True,train=False, transform=transformacao)Os dados de treino e teste foram armazenados nas variáveis dataset_treino e dataset_teste respectivamente, vamos visualizar alguns desses dados na etapa a seguir.
💡 Os passos 5, 6 e 7 não são obrigatória, você tem a opção de ir direto para o Passo 8.
Passo 5 - Para visualização dos dados vamos utilizar o Matplotlib e o Random, uma biblioteca de visualização e um modulo de geração de valores pseudo randômicos respectivamente.
import matplotlib.pyplot as plt
import randomPasso 6 - Definimos um objeto do tipo figura, que chamamos de fig e um eixo que chamamos de axs. Para isso utilizamos a função subplots definindo os argumentos da função como:
a quantidade de linhas (nrows), colunas (ncols) e tamanho da figura (figsize).
fig, axs = plt.subplots(nrows=1, ncols=9, figsize=(15,4))Passo 7 - Definimos a variável random_idx para armazenar um valor randômico dos n dados disponiveis que foram armazenados na variável dataset_treino. No eixo ax é utilizado o imshow para gerar a visualização do dado sorteado, em escala cinza. Na sequência o set_title é utilizado para imprimir o rótulo do dado com uma fonte 12 logo acima da figura.
Usar o for para iterar sobre ’n’ imagens
for ax in axs:
random_idx = random.randint(0,len(dataset_treino.data))
ax.imshow(dataset_treino.data[random_idx].numpy(),cmap='gray')
ax.set_title(f'Classe: {dataset_treino.targets[random_idx]}', size=12)Passo 8 - Agora podemos criar nossa estrutura de aprendizado, ou seja, o nosso modelo. Para isso vamos importar nn onde temos modulos básicos para construção das redes neurais e o functional onde encontramos nossas funções de ativação.
💡 Lembre:
1º Criamos uma classe que represente nossa rede (Class Modelo) extendendo para o modulo do Pytorch;
2º Criamos o método construtor _init_ definindo as camadas da nossa estrutura, quantidades de neurônios e classes;
3º Criamos o método forward que define como essas camadas serão conectadas.
import torch.nn.functional as F
class Modelo(torch.nn.Module):
def __init__(self):
super(Modelo, self).__init__()
self.camada_entrada = torch.nn.Linear(28*28, 128)
self.camada_h1 = torch.nn.Linear(128, 64)
self.camada_h2 = torch.nn.Linear(64, 32)
self.camada_saida = torch.nn.Linear(32, 10)
def forward(self, x):
x = F.relu(self.camada_entrada(x))
x = F.relu(self.camada_h1(x))
x = F.relu(self.camada_h2(x))
x = F.softmax(self.camada_saida(x))
return xPasso 9 - Definido a nossa estrutura (modelo) instânciamos um objeto da classe, no nosso caso do tipo Modelo. Podemos utilizar a função print para visualizar essa estrutura.
modelo = Modelo()
print(modelo)Passo 10 - Agora queremos fazer o treinamento do modelo, antes disso, vamos falar sobre os modulos Dataset e DataLoader. Eles permitem que você use conjuntos de dados pré-carregados, bem como seus próprios dados.
Enquanto o Dataset armazena as amostras e seus rótulos correspondentes o DataLoader envolve um iterável em torno de ’lotes de amostras’ para facilitar o acesso aos dados.
Ao treinar um modelo, normalmente queremos passar amostras em “minilotes”, reorganizar os dados a cada época, com o objetivo de reduzir o superajuste do modelo e usar subprocessos para acelerar a recuperação de dados.
from torch.utils.data import DataLoader
dados_treino = DataLoader(dataset_treino, batch_size=128, shuffle=True)
dados_teste = DataLoader(dataset_teste, batch_size=128, shuffle=False)💡 Carregamos esse conjunto de dados no DataLoader e podemos iterar pelo conjunto de dados conforme necessário.
Passo 11 - No módulo ’torch.nn’ devemos escolher a função de custo e o otimizador que será utilizado no nosso modelo.
Utilizaremos o CrossEntropyLoss, que calcula a perda de entropia cruzada entre logits de entrada e o alvo, na função de custo. O otimizador Adam foi o escolhido que é um método de descida de gradiente estocástico baseado na estimativa adaptativa de momentos de primeira e segunda ordem.
loss_func = torch.nn.CrossEntropyLoss()
otimizador = torch.optim.Adam(modelo.parameters())Passo 12 - Agora precisamos criar nossa função de treinamento funcao_treinamento. Nela informamos nossos parametros de treinamento como o critério de parada e tamanho de ‘mini-lote’.
Nessa função geramos um loop de iteração com objetivo de formatar cada um dos nossos dados, salvar etapas do treinamento e aplicar subprocessos do treinamento.
💡 Passo a passo:
1º Importar a biblioteca numpy para formatação dos dados
2º Definir função de treinamento
3º Criar as variáveis de controle, neste caso configuramos uma variável para armazenar a valor de perda instântanea valor_loss, uma lista que armazena o historico dos valores de perda lista_loss e uma lista para armazenar o historico dos valores de acurácia lista_acc.
4º Criamos então o loop de interação, esta pode ser uma etapa mais complexa então vamos criar sub-tópicos:
4.1 - Através da estrutura for vamos separar os dados brutos e os seu rótulos armazenados na variável dados_treino, logo criamos as variáveis dados e labels respectivamente.
4.2 - Em seguida, alteramos o dimensionamento dos dados brutos (1,28,28) para (1,784). Alteração necessaria para poder percorrer os dados na estrutura de rede neural.
4.3 - Agora definimos os gradientes de todos torch.Tensor para zero, para iniciar o processo de treinamento.
4.4 - Em seguida propagamos nossos dados na estrutura de rede neural armazenando a saida do modelo em saida_modelo.
4.5 - Vamos então armazenar os valores preditos para calcular a acurácia através do torch.max() que retorna o valor maximo da nossa função softmax para fazer nossa comparação.
4.6 - Na sequência calculamos nosso valor de perda na variável loss através do loss_func definido anteriormente comparando a saída do modelo com as nossas labels.
4.7 - Conhecendo então nossos índices de erro podemos retropropagar esta taxa de error através do método loss.backward() e na sequência atualizamos o peso do nosso otimizador através do método otimizador.step().
4.8 - Calculamos então quantos acertos tivemos com as predições, aplicando um somatório de quantidade de predições corretas, buscando todas predicoes == labels == TRUE
4.9 - Verificamos então a quantidade de predições corretas para aquele minilote
4.10 - Adicionamos os valores instantâneos de acurácia e perda nas listas reservadas lista_loss e lista_acc.
4.11 - Ao final imprimimos na tela o valores de Época, Perda e Acurácia encontrada.
import numpy as np
def funcao_treinamento(epoch, batch_size):
valor_loss = 0
lista_loss = []
lista_acc = []
for dados, labels in dados_treino:
dados = dados.view(dados.shape[0], -1)
otimizador.zero_grad()
saida_modelo = modelo(dados)
_, predicoes = torch.max(saida_modelo.data, 1)
loss = loss_func(saida_modelo, labels)
loss.backward()
otimizador.step()
acertos = (predicoes == labels).sum().item()
acc = acertos/batch_size
lista_acc.append(acc)
lista_loss.append(loss.item())
else:
print(f'Época {epoch} - Loss treino: {np.mean(lista_loss)} Acurácia: {np.mean(lista_acc)}')Passo 13 - Definido então a estrutura de treinamento, chegamos no momento de efetivamente treinar o modelo, para isso criamos uma estrutura de repetição que represente a quantidade de épocas que queremos treinar, chamamos a função de treinamento definada anteriormente e passamos os valores de época e tamanho do lote.
for epoch in range(10):
funcao_treinamento(epoch,128)💡 O terminal apresenta os valores de perda e acurácia na etapa de treinamento, na sequência precisamos verificar as mesmas métricas para dados desconhecidos. Para isso iremos propagar os dados de teste sem atualização dos gradientes.
Passo 14 - Utilizando o torch.no_grad() garantimos que o gradiente não será atualizado. Para isso criamos um bloco de código através do with.
A codificação é semelhante o que fizemos na étapa de treinamento então não explicaremos o passo a passo, visto que isso já foi feito anteriormente.
acertos = 0
with torch.no_grad():
lista_acertos = []
for dados, labels in dados_teste:
dados = dados.view(dados.shape[0], -1)
saida_modelo = modelo(dados)
_, predicoes = torch.max(saida_modelo.data, 1)
acertos = (predicoes == labels).sum().item()
lista_acertos.append(acertos/128)
print(f'Acurácia Modelo: {100 * np.mean(lista_acertos)}%')💡 Chegamos então ao final do nosso modelo. Com a etapa de teste concluída podemos dizer o valor de acurácia ou qualquer outra métrica escolhida que determine a robustez do nosso modelo para dados desconhecidos !
Parabénssss !! 🎉 Você acaba de concluir todo o processo de codificação para o seu primeiro modelo de IA 🙂.
Tensorflow
Para o nosso segundo exemplo vamos utilizar o Tensorflow que segundo a própria plataforma é uma plataforma completa de aprendizado de máquina onde enncontramos soluções para acelerar as tarefas de aprendizado em cada etapa do fluxo de trabalho.
💡 Leia a documentação para mais detalhes neste link.
Para entregar um bom nível de comparação com o Pytorch, vamos utilizar o mesmo Dataset utilizado anteriormente, o MNIST.
Passo 1 - Vamos importar o Tensorflow e as bibliotecas escolhidas para formatação e visualização dos dados, sendo o Numpy e o Matplotlib respectivamente.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltPasso 2 - Para carregar o dataset MNIST pelo Tensorflow podemos utilizar o módulo do keras.datasets.mnist.load_data(). Teremos duas tuplas como retorno, a primeira contendo os dados de treinamento e a segunda os dados reservados para teste.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()Passo 3 - Para visualizar, uma amostra, dos dados recebidos vamos utilizar o matplotlib, o mesmo utilizado na framework anterior, com isso não iremos entrar em detalhe da codificação.
linhas = 2
colunas = 5
fig, axs = plt.subplots(linhas, colunas, figsize=(16, 4))
axs = axs.flatten()
for i in range(linhas * colunas):
axs[i].imshow(x_train[i], cmap='gray_r')
axs[i].set_title(str(y_train[i]))
axs[i].axis('off')
plt.show()Passo 4 - Aplicaremos a técnica de normalização dos dados de teste e treinamento. É uma etapa importante para evitar viés e reduzir o custo computacional.
💡 Como se trata de dados de imagem temos como maior valor de pixel a constante 255, logo, faremos a divisão de todos os dados, exceto os rótulos por este valor.
x_train, x_test = x_train / 255.0, x_test / 255.0Passo 5 - No Tensorflow a estrura de Redes Neurais é instânciada a partir do keras.Sequential onde é adicionado, camada por camada a partir de métodos pré definidos como o keras.layers.Flatten e keras.layers.Dense, responsáveis por identificar a dimensionalidade dos dados de entrada, definir quantidades de neurônios e a função de ativação por camada.
💡 No Tensorflow essas definições podem ser definidas utilizando argumentos dos próprios métodos, como visto abaixo.
modelo_3 = tf.keras.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28, 1,)),
tf.keras.layers.Dense(200, activation='relu'),
tf.keras.layers.Dense(60, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])Passo 6 - Podemos verificar a estrutura de Rede Neural criada a partir do método summary() do modelo.
modelo_3.summary()
Passo 7 - Para definir o otimizador, função de custo e métrica que será aplicada, utilizamos o método compile() e definimos essas informações nos argumentos reservados para tal.
modelo_3.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])Passo 8 - Para treinar o modelo utilizamos o método fit() e informamos os dados de treinamento e teste, bem como as épocas, a quantidade de dados por minilote e o verbose útil para definir se a evolução em cada época de treinamento serão apresentadas no terminal da máquina.
history = modelo_3.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
batch_size=64, verbose=2)Passo 9 - Podemos visualizar um grafico da evolução do treinamento a partir history.history[‘accuracy’] e do history.history[‘val_accuracy’]
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')Passo 10 - A precisão do modelo pode ser estimada a partir do método evaluate.
test_loss, test_acc = modelo_3.evaluate(x_test, y_test, verbose=2)
print(test_acc)Parabénssss !! 🎉 Você acaba de aprender uma nova framework 🙂.

Scikit Learn
Para o nosso último exemplo vamos utilizar o Scikit-learn que segundo a própria documentação disponibiliza ferramentas simples e eficientes para análise preditiva de dados, sendo acessível a todos e reutilizável em vários contextos.
É uma estrutura de código aberto, construído em NumPy, SciPy e Matplotlib.
💡 Iremos utilizar o mesmo Dataset MNIST, apresentado nos exemplos anteriores.
Passo 1 - Inicialmente precisamos importar o dataset MNIST, para isso acessamos o módulo fetch_openml de sklearn.datasets, como apresentado abaixo.
from sklearn.datasets import fetch_openmlPasso 2 - Usando o fetch_openml informamos o nome do dataset desejado, no nosso caso o mnist_784 e qual retorno escolhido em return_X_y, TRUE para retornar os dados brutos e os rótulos, ou FALSE para apenas o retorno dos dados.
💡 X = Dados e y = rótulos
X, y = fetch_openml("mnist_784", return_X_y=True)Passo 3 - A etapa de normalização também será aplicada no ScikiLearn, semelhante ao que foi feito no Tensorflow.
X = X / 255.0Passo 4 - Podemos separar os dados de treinamento e teste de forma fácil, a partir do método train_test_split do modulo sklearn.model_selection. Sendo test_size o percentual dos dados reservados para teste, random_state uma forma de deixar a aleatoriedade da escolha dos dados previsíveis (pseudo-aleatoriedade) e o shuffle responsável pelo embarelhamento dos dados, com objetivo de aplicar um balanceamento correto e evitar viés.
💡 Temos 4 variáveis de retorno:
Dados de treinamento e teste (X_train , X_test)
Rótulos de treinamento e teste (y_train , y_test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42, shuffle=True)Passo 5 - Utilizaremos neste exemplo a estrutura de rede neural conhecida com MultiLayer Perceptron ou MLP, para isso basta importar o MLPClassifier do modulo sklearn.neural_network.
from sklearn.neural_network import MLPClassifierPasso 6 - Instânciamos um objeto do tipo MLPClassifier informando em seus argumentos a quantidade de neurônios por camada oculta, quantidade de épocas de treinamento, o otimizador, verbose (similar ao Tensorflow), random_state (explicado no train_test_split) e o valor da taxa de aprendizado.
💡 A arquitetura do modelo é salva em mlp
mlp = MLPClassifier(
hidden_layer_sizes=(60,10),
max_iter=10,
solver="adam",
verbose=True,
random_state=65,
learning_rate_init=0.001,
) # arquiteturaPasso 7 - O treinamento é feito utilizando o método fit, informando os dados e os rótulos de treinamento.
mlp.fit(X_train, y_train) #model
print("Taxa de Treinamento (Acurácia): %f" % mlp.score(X_train, y_train))
print("Taxa de Teste (Acurácia): %f" % mlp.score(X_test, y_test))Passo 8 - Podemos utilizar novamente o matplotlib para visualização da evolução do aprendizado. Para isso utilizamos o loss_curve_ e geramos a figura com o método plot
mlp.loss_curve_
import numpy as np
plt.plot(np.arange(len(mlp.loss_curve_)),mlp.loss_curve_)Com isso chegamos ao final deste post, parabéns por ter chegado até aqui 🎉 . Espero que este conteúdo tenha contribuído na sua jornada de aprendizado em Inteligência Artificial. Continue acompanhando para mais informações, até a próxima 🙂 🎉 🥳.
