Libraries Data Science - Plot View
By Adson Nogueira Alves
Introdução a Bibliotecas para Ciência de Dados - Parte 3 de 3


Nosso objetivo será aprender 2 novas bibliotecas, ambas para visualização de dados o Matplotlib e o Seaborn. Importante ler a documentação completa para o pleno aprendizado.
Matplotlib
Segundo a documentação Matplotlib é uma biblioteca abrangente para criar visualizações estáticas, animadas e interativas em Python, tornando tudo mais fácil.
Semelhante aos estudos anteriores com Numpy e Pandas, a biblioteca Matplotlib pode ser instalada utilizando o Anaconda Distribution
conda install matplotlib
- Ou utilizando o pip
pip install matplotlib
Caso não queira instalar localmente você tem a opção de utilizar o Colab, ou “Colaboratory”, que permite que você execute todos os códigos em Python diretamente no seu navegador. Neste link você tem um vídeo introdutório da ferramenta.
Para acessar as funções do Matplotlib é necessário importar a biblioteca para o código python e o modulo pyplot. Onde plt será apenas uma abreviação para melhor legibilidade do código.
import matplotlib.pyplot as plt
O matplotlib foi construído pensando na compatibilidade com NumPy, Listas e Pandas Series. O comando básico da biblioteca é a função plot(), que gera um gráfico a partir dos dados que são passados como parâmetros.
Vamos admitir a representação gráfica de 2 eixos x e y, valores aleatórios serão atribuídos a fim de representar dados contínuos no eixo x, veja abaixo:
>> x = np.linspace(0,7,50)
>> y = x ** 2
>> print(x)
[0. 0.14285714 0.28571429 0.42857143 0.57142857 0.71428571
0.85714286 1. 1.14285714 1.28571429 1.42857143 1.57142857
1.71428571 1.85714286 2. 2.14285714 2.28571429 2.42857143
2.57142857 2.71428571 2.85714286 3. 3.14285714 3.28571429
3.42857143 3.57142857 3.71428571 3.85714286 4. 4.14285714
4.28571429 4.42857143 4.57142857 4.71428571 4.85714286 5.
5.14285714 5.28571429 5.42857143 5.57142857 5.71428571 5.85714286
6. 6.14285714 6.28571429 6.42857143 6.57142857 6.71428571
6.85714286 7. ]
Logo, para visualizar o gráfico basta fazer:
plt.plot(x,y)
plt.show()
Veja como ficou a representação gráfica dos nossos dados.

Pode ser interessante alterar a cor, marcador e estilo de linha do gráfico, para isso vamos alterar atributos de plot como o marker, linestyle e color. É importante definir qualquer representação gráfica a partir de legendas, para isso os métodos xlabel(), ylabel() e title() serão úteis, veja como é feito:
plt.plot(x,y, marker='*',linestyle= '-.',color='red' )
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Meu primeiro grafico com Matplot')
plt.show()
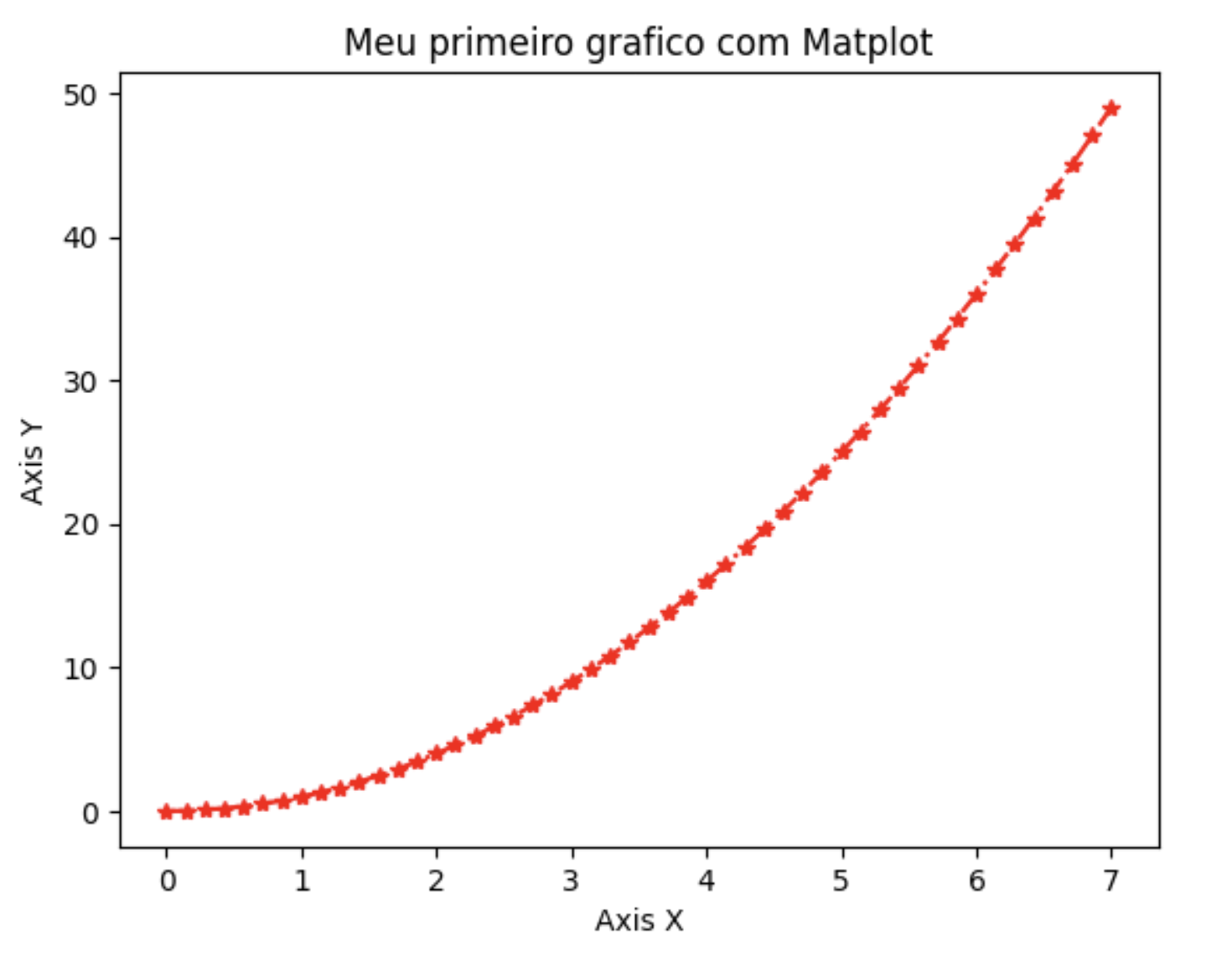
💡 Observe que um método show() serve para fazer a pré visualização gráfica.
Outra forma de alterar o estilo seria de forma abreviada, vou deixar um exemplo de código para você testar. O mesmo gráfico é esperado.
plt.plot(x,y, 'r*--')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Meu primeiro grafico com Matplot')
plt.show()
Nos gráficos anteriores temos um único eixo de valores representando um conjunto de dados. Admita um cenário onde é importante representar vários conjuntos de dados no mesmo eixo, exemplo, a representação dos dados anteriores com o seno(x) e um potência 3 de x. Veja o resultado.
plt.plot(x,y,'r',x, np.sin(x),'g',x,x**3, 'b')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Meu primeiro grafico com Matplot')
plt.show()
A cor vermelha foi definida para o conjunto de dados anteriores, verde para o seno e azul para a potência 3.

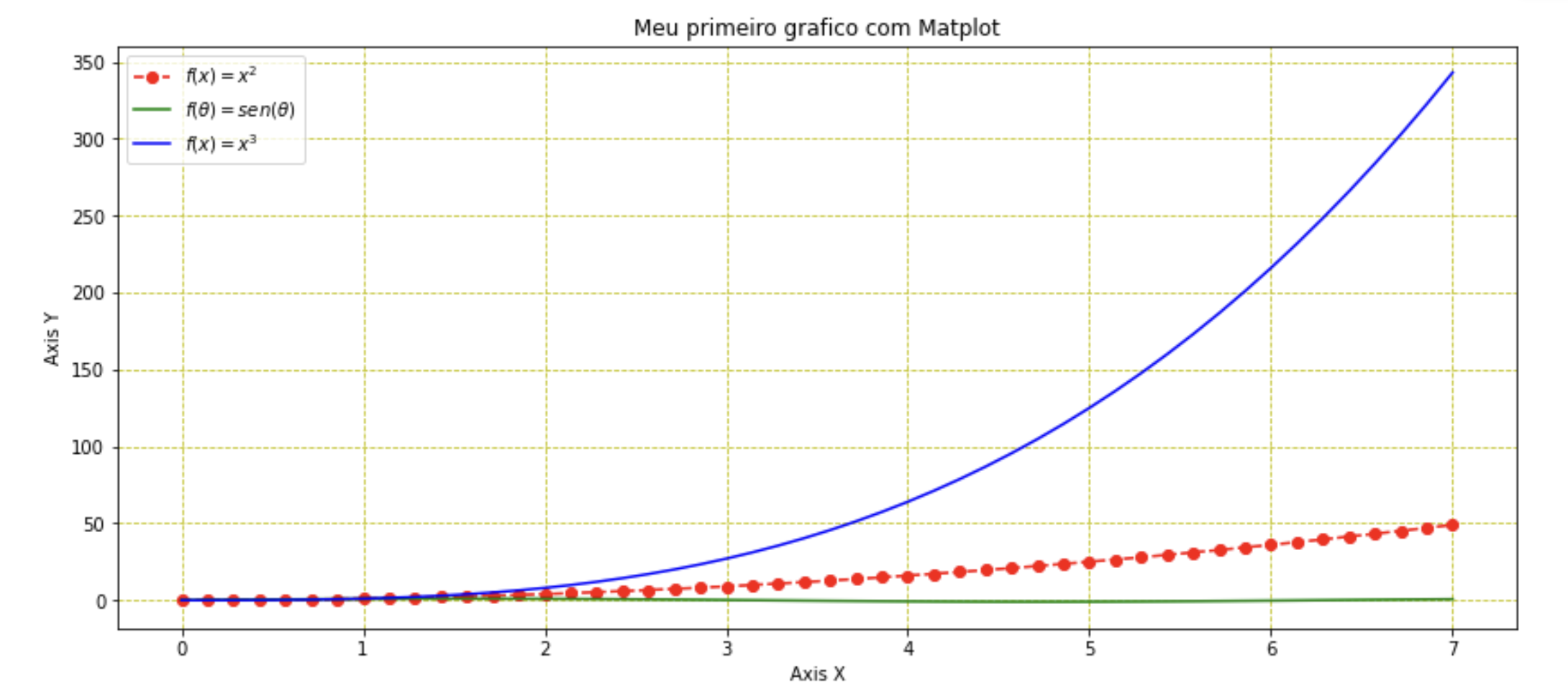
Com essas várias representações em um único eixo se torna vital adicionar uma legenda descritiva, o método legend() pode ajudar com isso. Para melhorar a leitura do gráfico linhas de grade podem ser adicionadas através do método grid(), veja como isso tudo é feito abaixo:
plt.plot(x,y, 'ro--', label=r'$f(x)=x^2$')
plt.plot(x, np.sin(x),'g', label=r'$f(\theta)=sen(\theta)$')
plt.plot(x,x**3, 'b', label=r'$f(x)=x^3$')
plt.legend(loc='best', fontsize=10) #best
plt.grid(linestyle='--',color= 'y')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Meu primeiro grafico com Matplot')
plt.show()
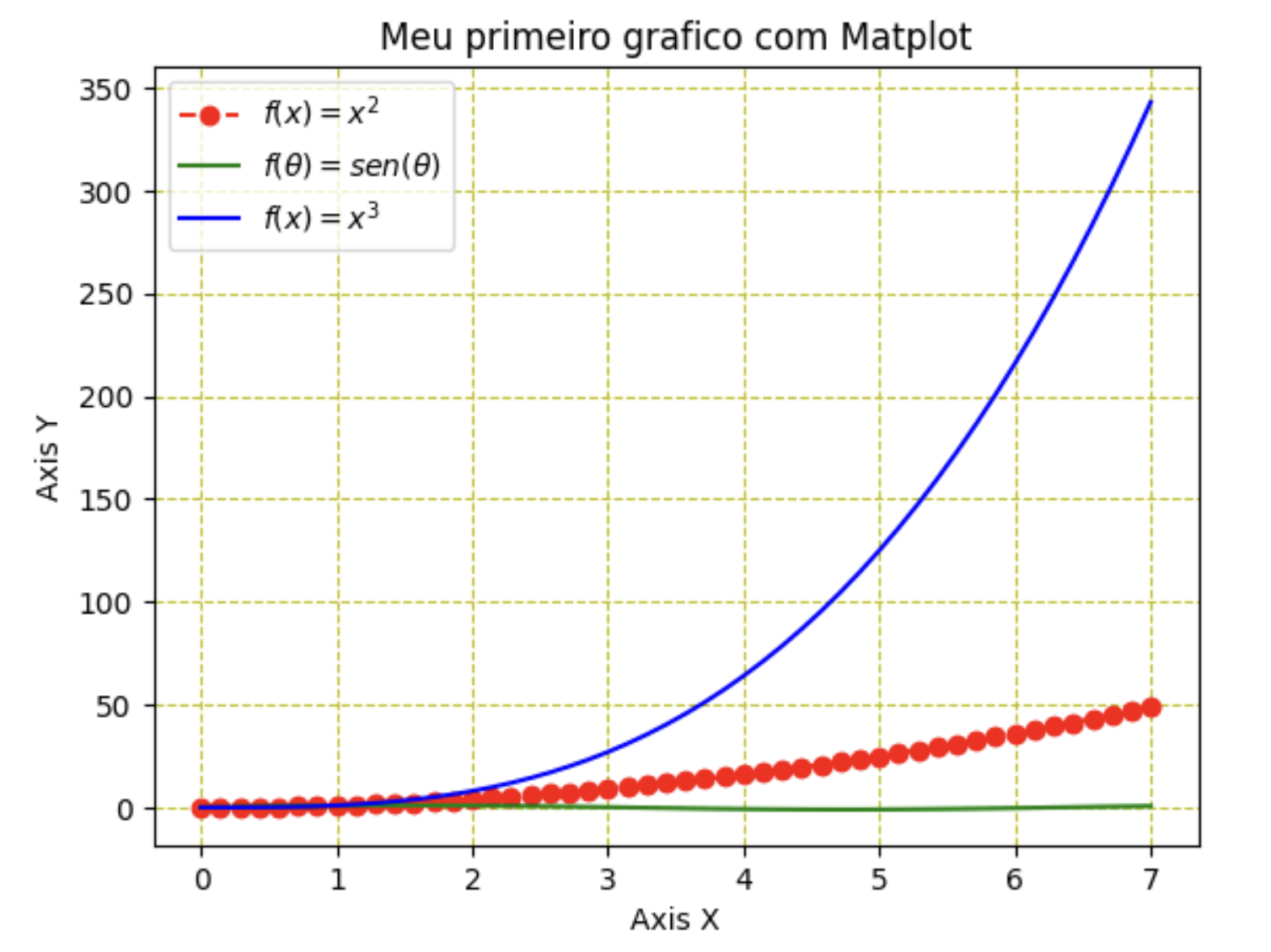
💡 Note que foi dedicado 1 plot para cada conjunto de dados a fim de definir a legenda individualmente.
Subplot e Figure
Falamos da representação de vários dados em 1 único eixo, e se quisermos representar vários dados em vários eixos? Existem algumas formas de fazer, uma delas é o subplot(Linha, Coluna, [1 .. n]). Com ele é possível definir a dimensão da figura de eixos e um “identificador” do eixo, veja como é feito.
plt.subplot(2, 2, 1)
plt.plot(x,y,'r')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Grafico A')
plt.subplot(2, 2, 2)
plt.plot(x,np.sin(x),'g')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Grafico B')
plt.subplot(2, 2, 3)
plt.plot(x,np.exp(x),'m')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Grafico C')
plt.subplot(2, 2, 4)
plt.plot(y,y**2,'y')
plt.xlabel('Axis X')
plt.ylabel('Axis Y')
plt.title('Grafico D')
plt.tight_layout()
plt.show()
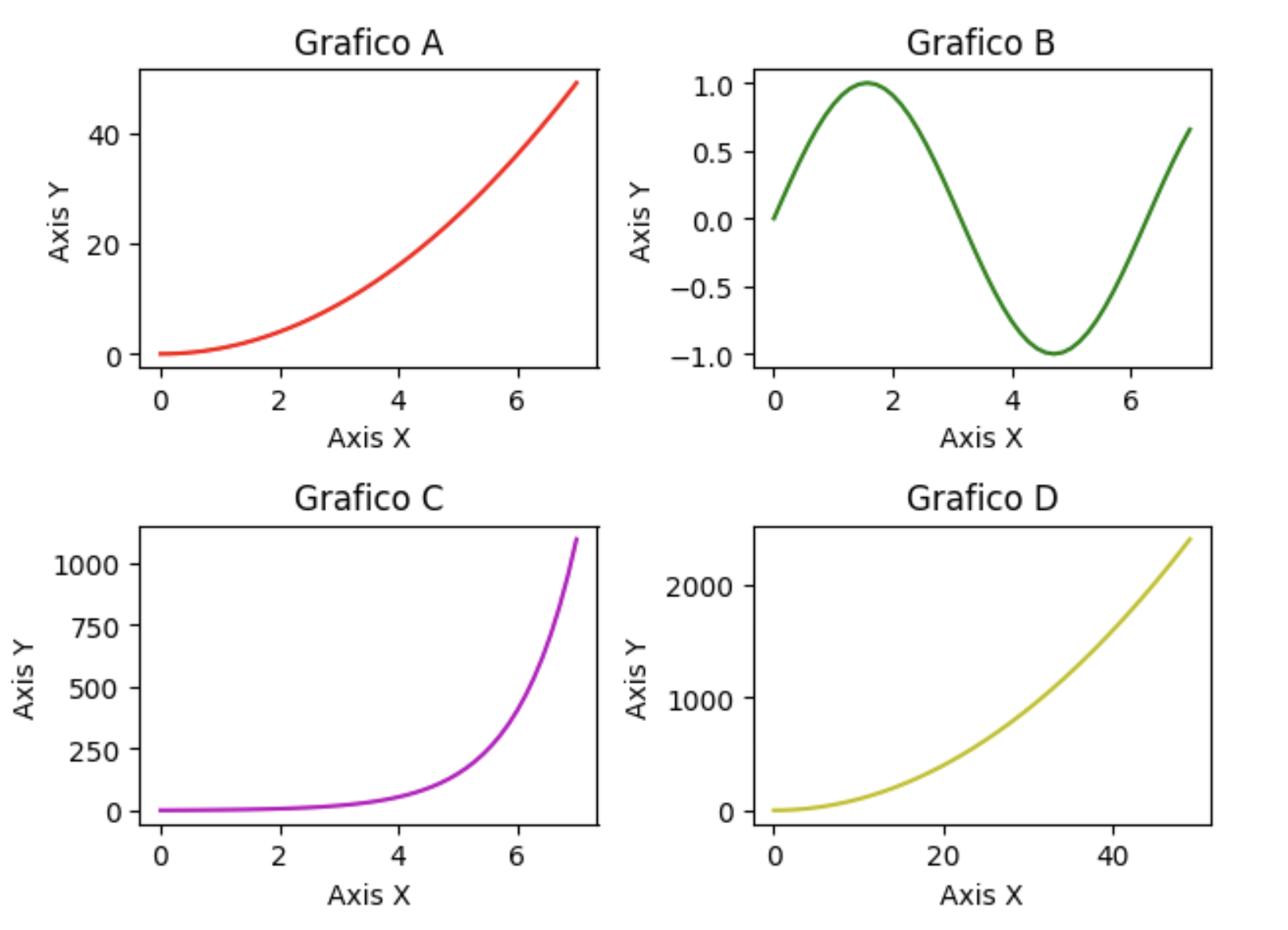
O .tight_layout() é útil para organizar o layout da figura, evitando que dados fiquem sobrescritos.
Note que os 4 eixos ficaram distribuídos em uma Figura semelhante a posições de uma matriz. Digo isso para destacar que a posição desses eixos podem ser manipulados e para controlar a posição desses eixos será necessário ter a manipulação dessa figura.
Isso será feito instantaneamente um objeto do tipo figure() e através dos métodos add_axes(margem da esquerda para direita, margem de baixo para cima, largura, altura) para definir as posições dos eixos. Na sequência basta gerar os plot`s() normalmente nos eixos declarados. Veja o exemplo abaixo.
fig = plt.figure()
ax1 = fig.add_axes([0.1,0.1,0.9,0.9]) # margem esq dir, margem baixo cima, largura, altura
ax2 = fig.add_axes([0.5,0.5,0.3,0.2])
ax1.plot(x,y,'r')
ax1.set_xlabel('Axis X')
ax1.set_ylabel('Axis Y')
ax1.set_title('Grafico f(x)=x^2')
ax2.plot(x,np.cos(x),'g')
ax2.set_xlabel('Axis X')
ax2.set_ylabel('Axis Y')
ax2.set_title('Grafico cosseno')
fig.show()
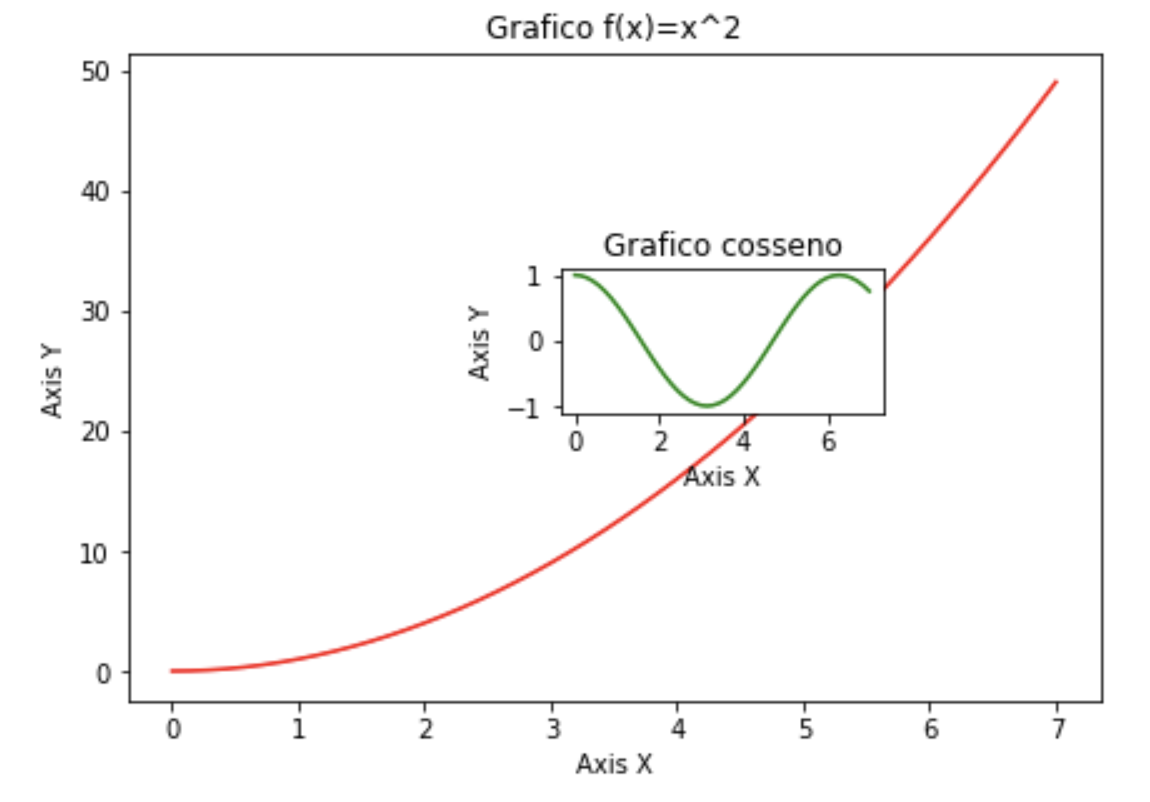
É possível usar esse mesmo controle de eixo para alterar dimensões da figuras geradas anteriormente, veja um exemplo:
fig = plt.figure(figsize=(12,5))
ax4 = fig.add_axes([0.1,0.1,0.9,0.9])
ax4.plot(x,y, 'ro--', label=r'$f(x)=x^2$')
ax4.plot(x, np.sin(x),'g', label=r'$f(\theta)=sen(\theta)$')
ax4.plot(x,x**3, 'b', label=r'$f(x)=x^3$')
ax4.legend(loc='best', fontsize=10) #best
ax4.grid(linestyle='--',color= 'y')
ax4.set_xlabel('Axis X')
ax4.set_ylabel('Axis Y')
ax4.set_title('Meu primeiro grafico com Matplot')
fig.show()
Subplots
Com a sutil adição de 1 “s” surge o subplots(). Com ele é facilitado a geração de uma figura com múltiplos eixos, visto que ao ser instanciado temos o retorno da figura e dos eixos, a partir das dimensões declaradas, veja exemplo abaixo:
fig, ax = plt.subplots(nrows=4, ncols =3, figsize=(14,10))
ax[1,1].plot(x,np.sin(x), c='r' )
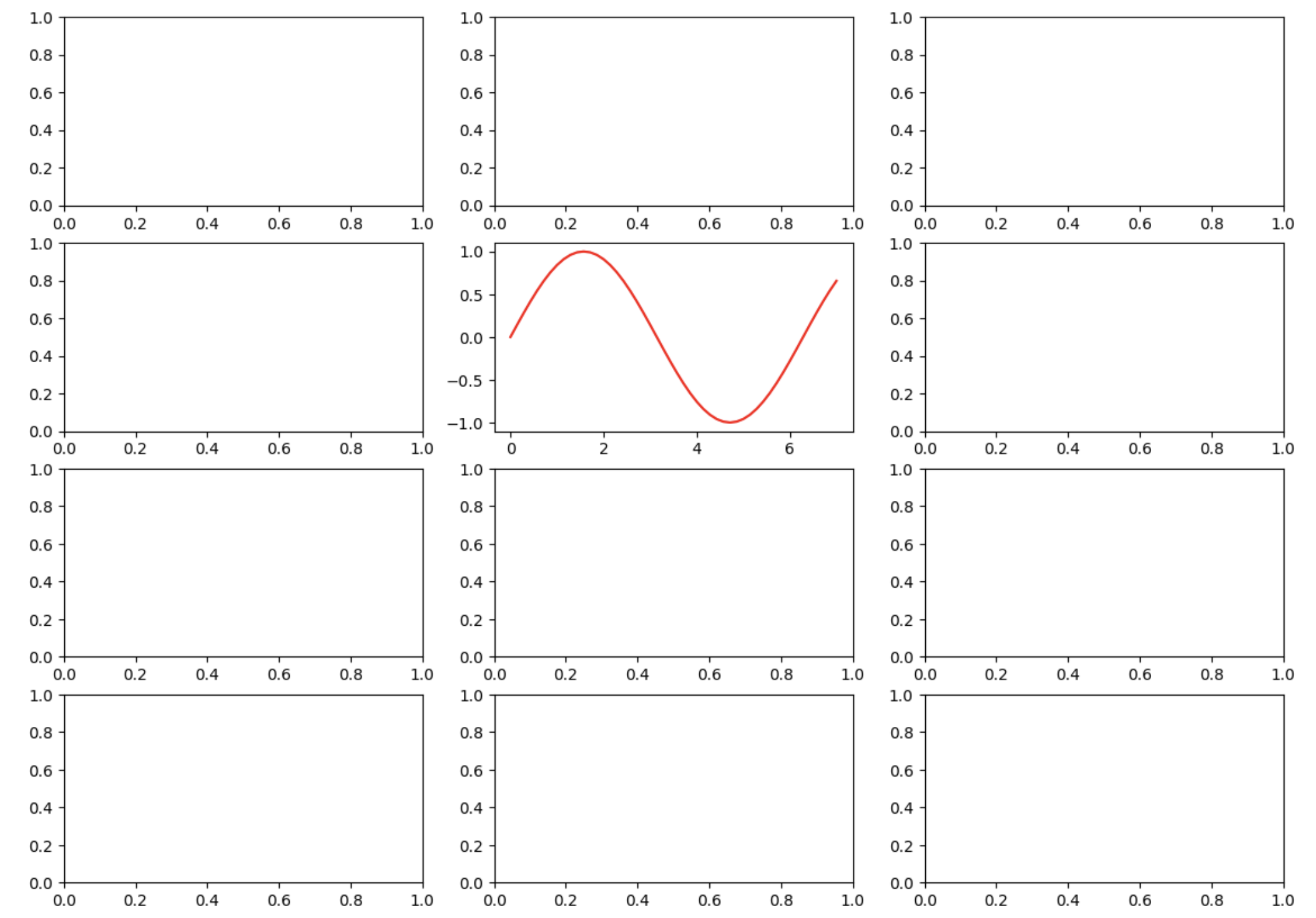
Observe que os atributos nrows, ncols e figsize são responsáveis por esse novo layout.
Outras formatações úteis
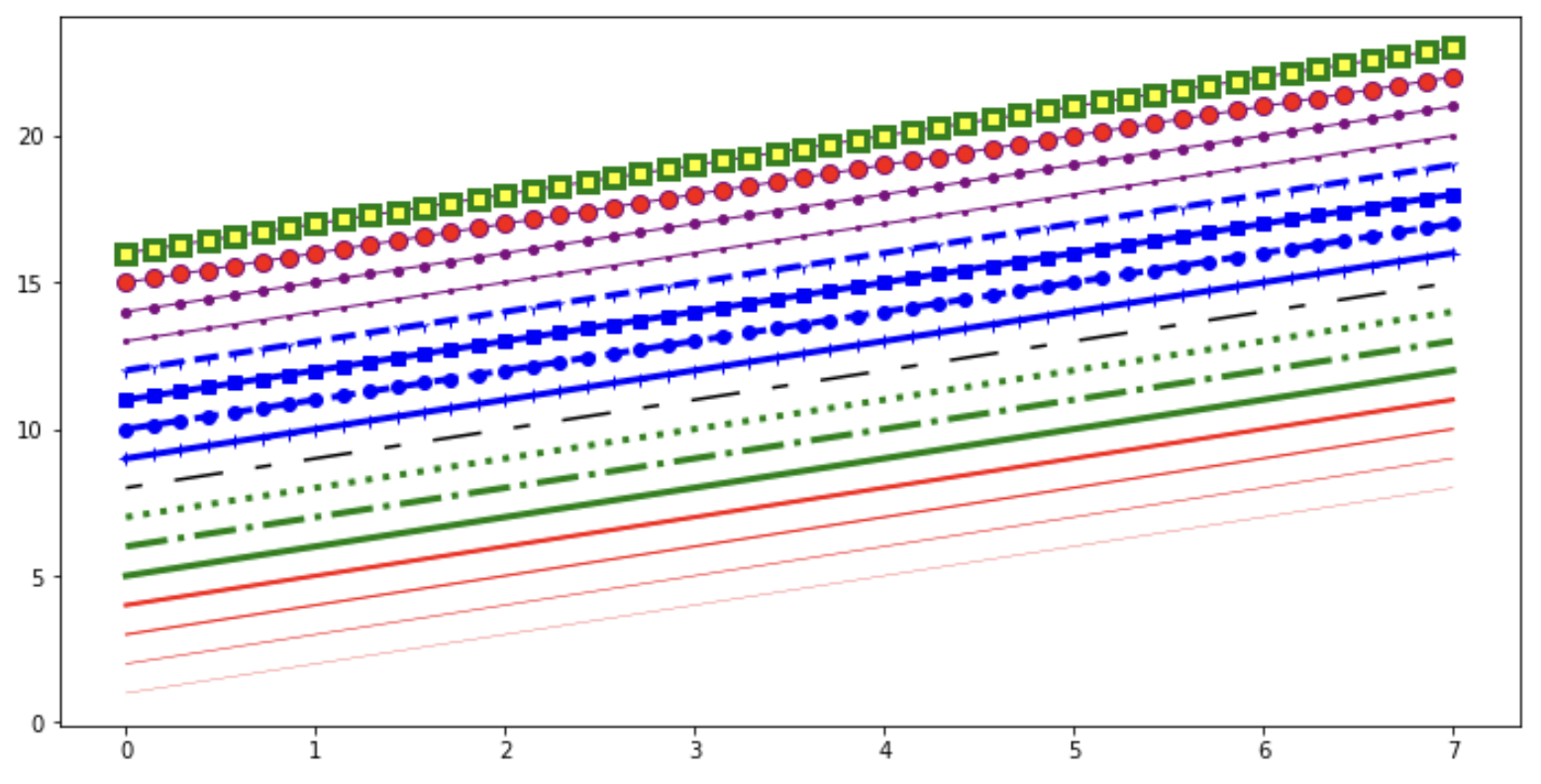
Outros estilos de formatação como largura e estilo de linha, tamanho, cor da face, espessura e cor de borda do marcador entre diversos outros também podem ser manipuladas, veja alguns exemplos abaixo:
fig, ax = plt.subplots(figsize=(12,6))
ax.plot(x, x+1, color="red", linewidth=0.25)
ax.plot(x, x+2, color="red", linewidth=0.50)
ax.plot(x, x+3, color="red", linewidth=1.00)
ax.plot(x, x+4, color="red", linewidth=2.00)
# opções de linestype: ‘-‘, ‘–’, ‘-.’, ‘:’, ‘steps’
ax.plot(x, x+5, color="green", lw=3, linestyle='-')
ax.plot(x, x+6, color="green", lw=3, ls='-.')
ax.plot(x, x+7, color="green", lw=3, ls=':')
# traços customizados
line, = ax.plot(x, x+8, color="black", lw=1.50)
line.set_dashes([5, 10, 15, 10])
ax.plot(x, x+ 9, color="blue", lw=3, ls='-', marker='+')
ax.plot(x, x+10, color="blue", lw=3, ls='--', marker='o')
ax.plot(x, x+11, color="blue", lw=3, ls='-', marker='s')
ax.plot(x, x+12, color="blue", lw=3, ls='--', marker='1')
# tamanho e cor dos marcadores
ax.plot(x, x+13, color="purple", lw=1, ls='-', marker='o', markersize=2)
ax.plot(x, x+14, color="purple", lw=1, ls='-', marker='o', markersize=4)
ax.plot(x, x+15, color="purple", lw=1, ls='-', marker='o', markersize=8,
markerfacecolor="red")
ax.plot(x, x+16, color="purple", lw=1, ls='-', marker='s', markersize=8,
markerfacecolor="yellow", markeredgewidth=3,markeredgecolor="green")
Outros atributos bem úteis são o dpi, responsável pelo controle de resolução da sua figura e do alpha, responsável pela transparência, veja:
fig2, ax = plt.subplots(dpi=100)
ax.plot(x,y)
ax.plot(x,np.sin(x))
ax.grid(ls='--',c='r',alpha=0.2)

Dados discretos
Até o momento nossos dados tiveram características contínuas, logo puderam ser bem apresentados pelo método plot(), porém nem todos os dados tem essas mesmas características, logo, para cenários discretos o método scatter() pode ser uma opção melhor. Neste exemplo, admita que xd e yd representam 50 valores aleatórios cada, usando o método random.rand() do Numpy a atribuição dos valores é facilitada, veja :
>> xd= np.random.rand(50)
>> yd= np.random.rand(50)
>> xd[:5]
array([0.01646771, 0.98598799, 0.87708422, 0.64647221, 0.27629171])
>> yd[:5]
array([0.63142039, 0.19112432, 0.48573527, 0.66302287, 0.88224583])
Utilizando o plot()
plt.plot(xd,yd)
plt.show()

Utilizando o scatter()
plt.scatter(xd,yd)
plt.show()
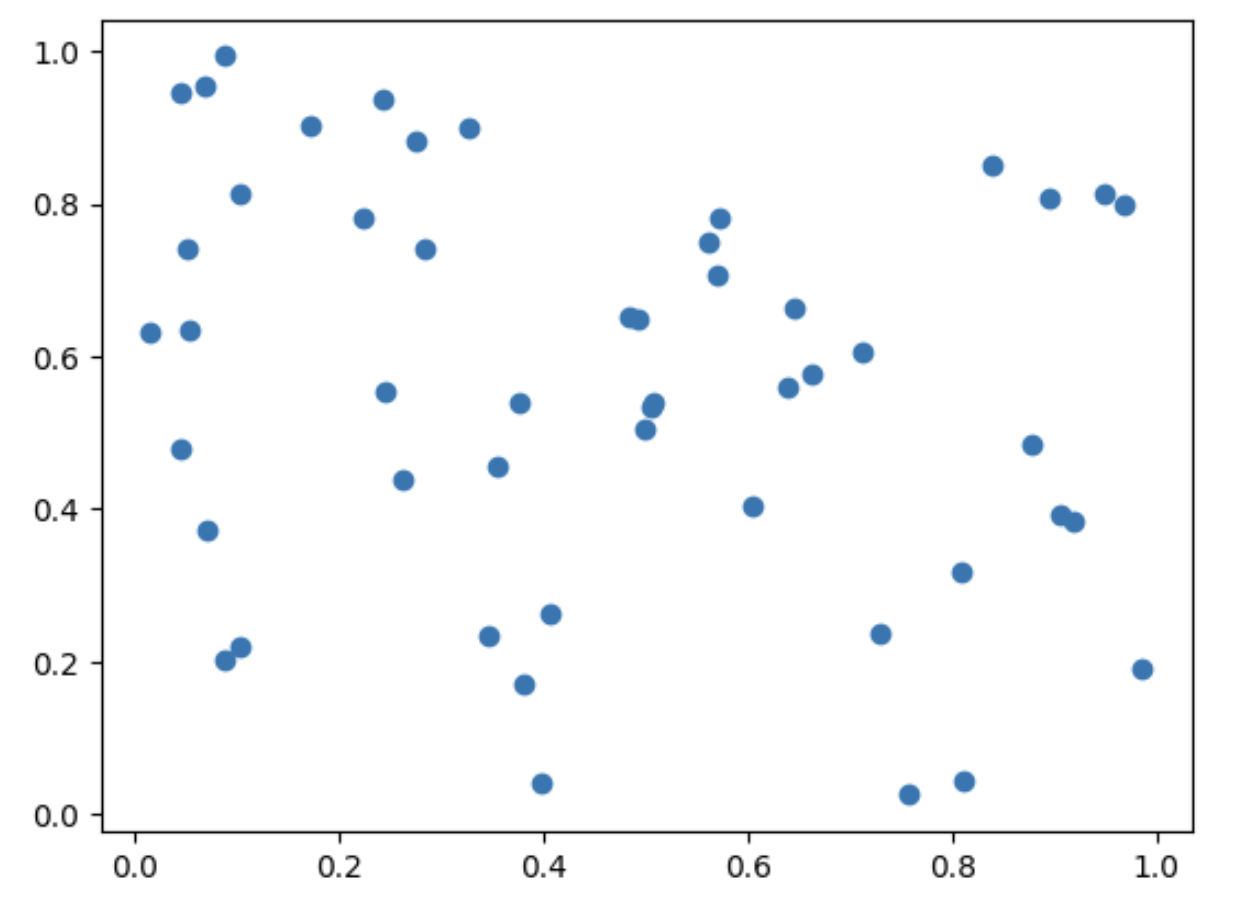
Utilizar o scatter() faz mais sentido não é mesmo ?!! =D
Para representação dos dados com uma perspectiva estatística, pode ser interessante usar o hist() ou o boxplot(), veja alguns exemplos.
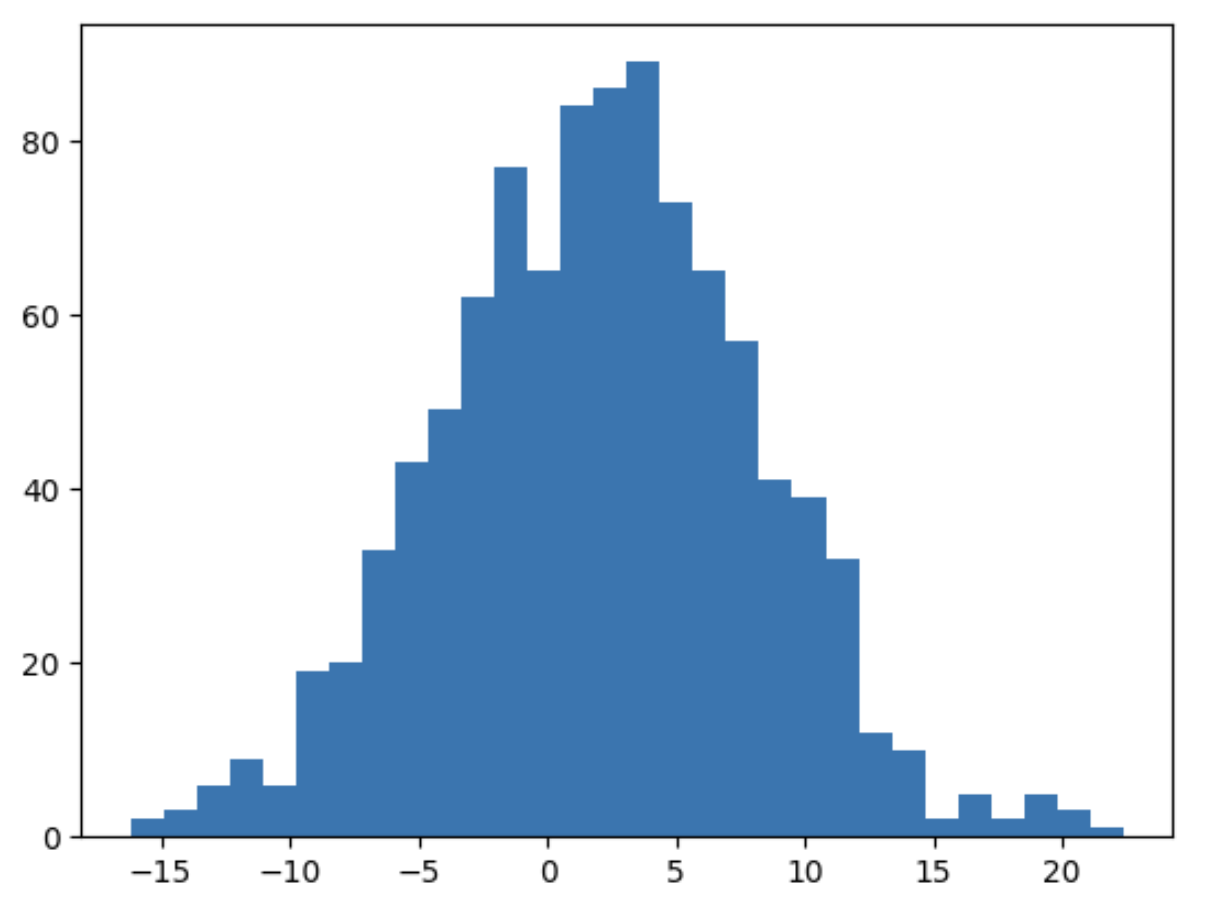
data = np.random.normal(2,6,1000)
plt.hist(data, bins=30)
plt.show()
data2 = [np.random.normal(loc=i,scale=1, size= 1000) for i in range(1,8,2)]
plt.boxplot(data2, vert=False)
plt.show()
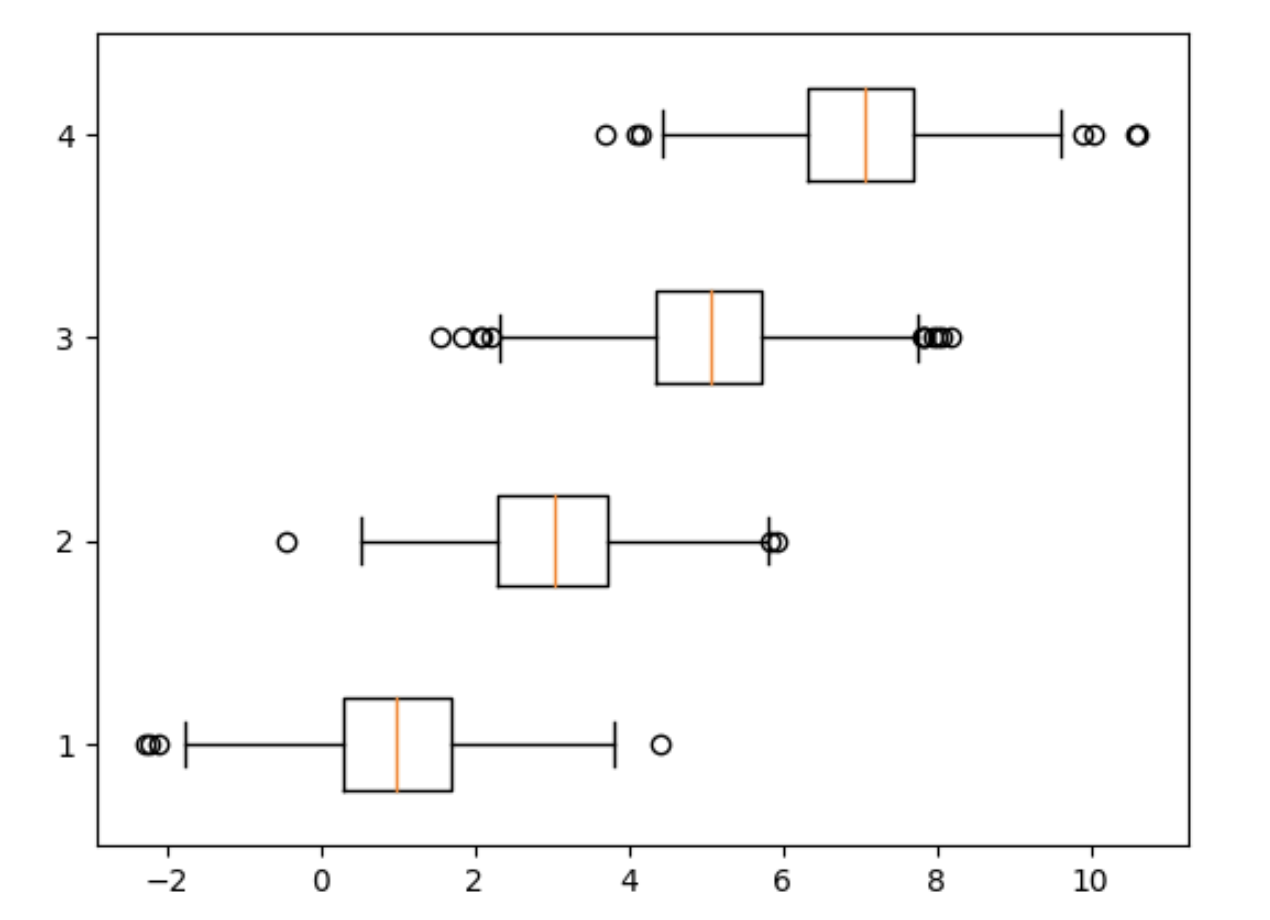
Alternativamente podemos customizar os rótulos dos eixos utilizando os método set_xticks(), set_yticklabels(), set_xticklabels(), veja o exemplo abaixo:
# avançado
fig, axes = plt.subplots()
axes.boxplot(data2, vert=False)
axes.set_xticks([0,5,10]) # formatando valores de eixo
axes.set_yticklabels(['PDF- Salario','PDF- Venda','PDF- Comissão','PDF- 13º'])
# axes.set_xticklabels(['PDF- Salario','PDF- Venda','PDF- Comissão','PDF- 13º'])
plt.show()

3 eixos
Outra opção é gerar uma visualização gráfica em 3 eixos, útil na representação de curvas com unidades diferentes. Para isso o matplotlib disponibiliza as funções twinx() para manter o eixo x como eixo comum e twiny() para manter o eixo y como o eixo comum, veja um exemplo abaixo:
# grafico com 3 eixos
fig8, ax = plt.subplots()
ax.plot(x,y, 'b-.' )
ax.set_ylabel("Azul", color='b')
for i in ax.get_yticklabels():
i.set_color('blue')
ax1 = ax.twinx()
ax1.plot(x,np.sin(x), 'r-' )
ax1.set_ylabel("Vermelho", color='r')
for i in ax1.get_yticklabels():
i.set_color('red')
ax.set_xlabel("X")
ax.set_title("3 eixos")
fig8.show()

O Matplotlib é uma biblioteca completa para visualização de dados em python, fizemos aqui uma introdução dessa poderosa ferramenta. Para continuar seus estudos consulte a documentação.
Seaborn
Segundo a documentação, seaborn é uma biblioteca de visualização de dados Python baseada no matplotlib, com uma interface de alto nível para gráficos estatísticos. Logo, tanto Matplotlib como Pandas estudados anteriormente conversaram muito bem.
A biblioteca Seaborn pode ser instalada utilizando o Anaconda Distribution
conda install seaborn
- Ou utilizando o pip
pip install seaborn
Para acessar as funções do Seaborn é necessário importar a biblioteca para o código python. Onde sns será apenas uma abreviação para melhor legibilidade do código.
import seaborn as sns
O seaborn contém um conjunto de dados que podem ser facilmente acessados neste link. Dessa forma iremos utilizar desse repositório e escolher tips, que são dados de gorjetas que atendentes de restaurantes receberam. Para isso, o método load_dataset() será útil, bastando informar o nome tips como parâmetro, veja o exemplo:
>> df = sns.load_dataset('tips') # Atenção - Data set da propria biblioteca
>> print(df.head())
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
>> df.describe().T
count mean std min 25% 50% 75% max
total_bill 244.0 19.785943 8.902412 3.07 13.3475 17.795 24.1275 50.81
tip 244.0 2.998279 1.383638 1.00 2.0000 2.900 3.5625 10.00
size 244.0 2.569672 0.951100 1.00 2.0000 2.000 3.0000 6.00
>> print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KB
💡 Usando pandas para entender melhor os nossos dados, veja que se trata de dados categóricos, float e int. São 244 dados com todas as series completas e ncom dados coerentes.
Para entender a distribuição de qualquer conjunto de dados do nosso Dataframe, uma alternativa é utilizar o kdeplot() que retorna a representação Gaussiana dos nossos dados, veja algumas forma de fazer:
# gaussiana
sns.kdeplot(df.total_bill)
sns.kdeplot(df['total_bill'])
sns.kdeplot(x= 'total_bill', data= df) # sugestão
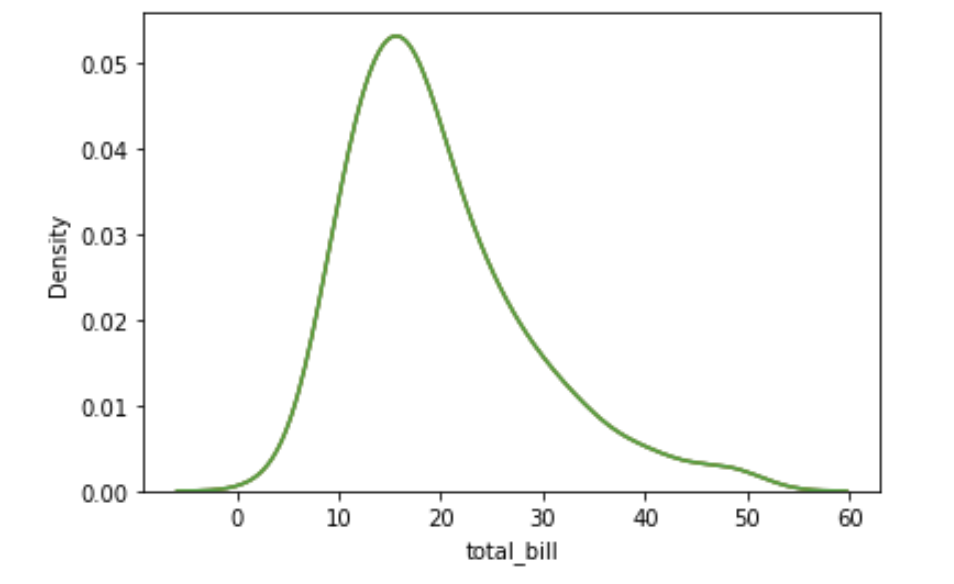
Note que apenas os dados de total_bill foram representados, porém também é possível apresentar todos os dados do dataframe em um único gráfico de gaussiana, certamente dados categóricos ou objetos serão ignorados. Veja o exemplo:
sns.kdeplot(data= df) # sugestão
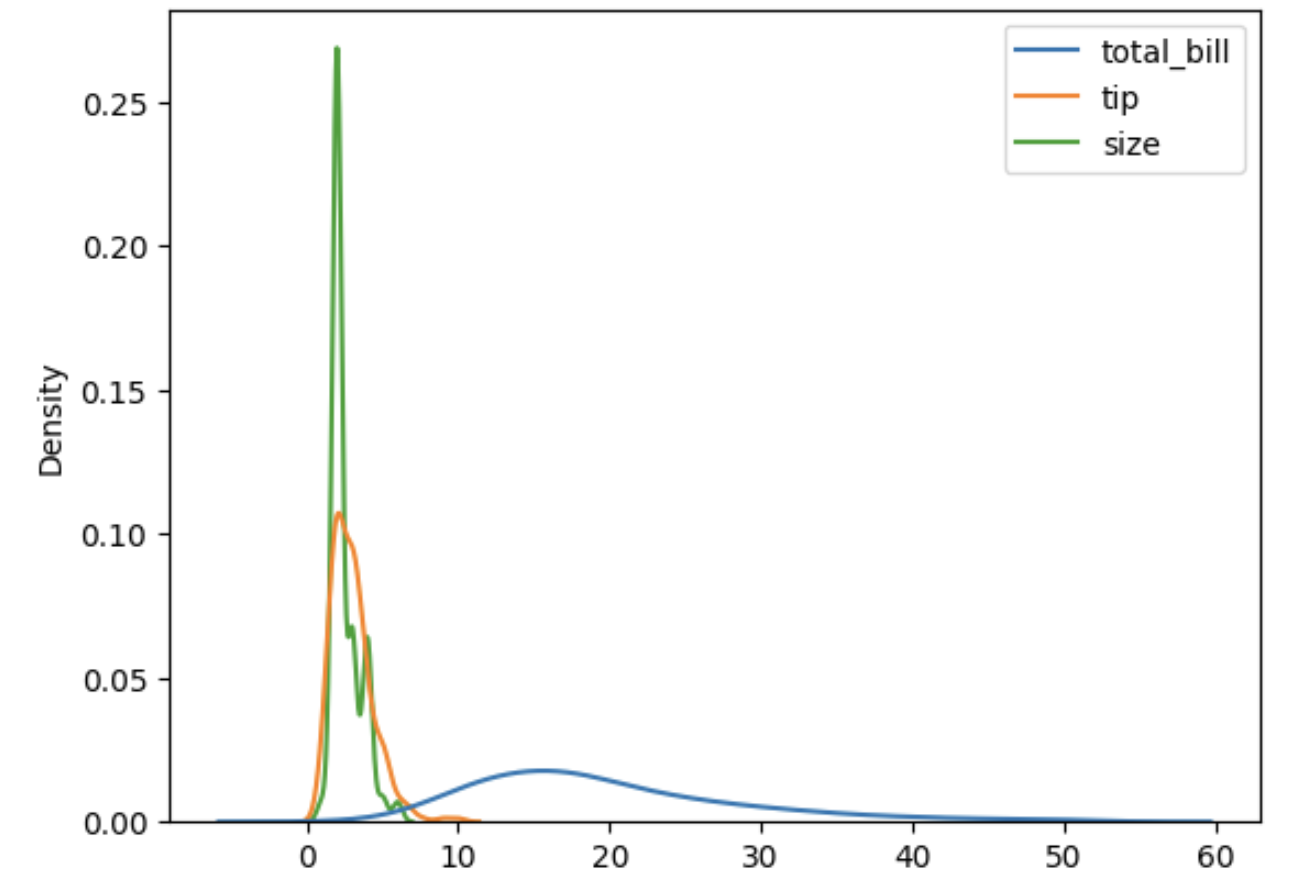
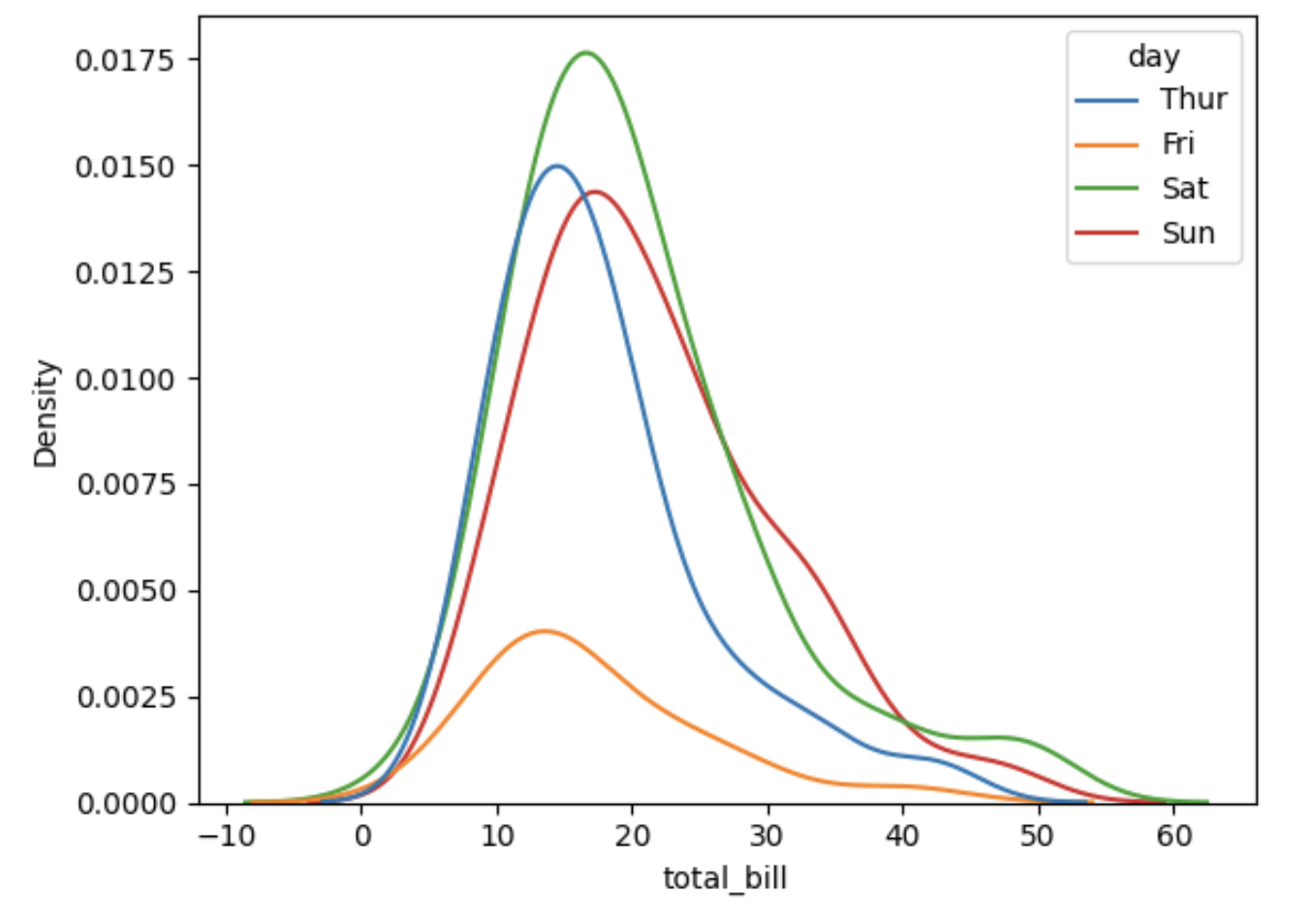
Outra visualização útil é gerar a correção dos dados do nosso dataframe, ou seja, admita que nosso objetivo seja entender a distribuição dos dados total_bill por dia da semana, para isso utilizamos a coluna “day” do nosso dataframe e atribuímos para ao parâmetro hue de kdeplot(), veja o exemplo:
sns.kdeplot(data= df,x='total_bill', hue='day') # sugestão
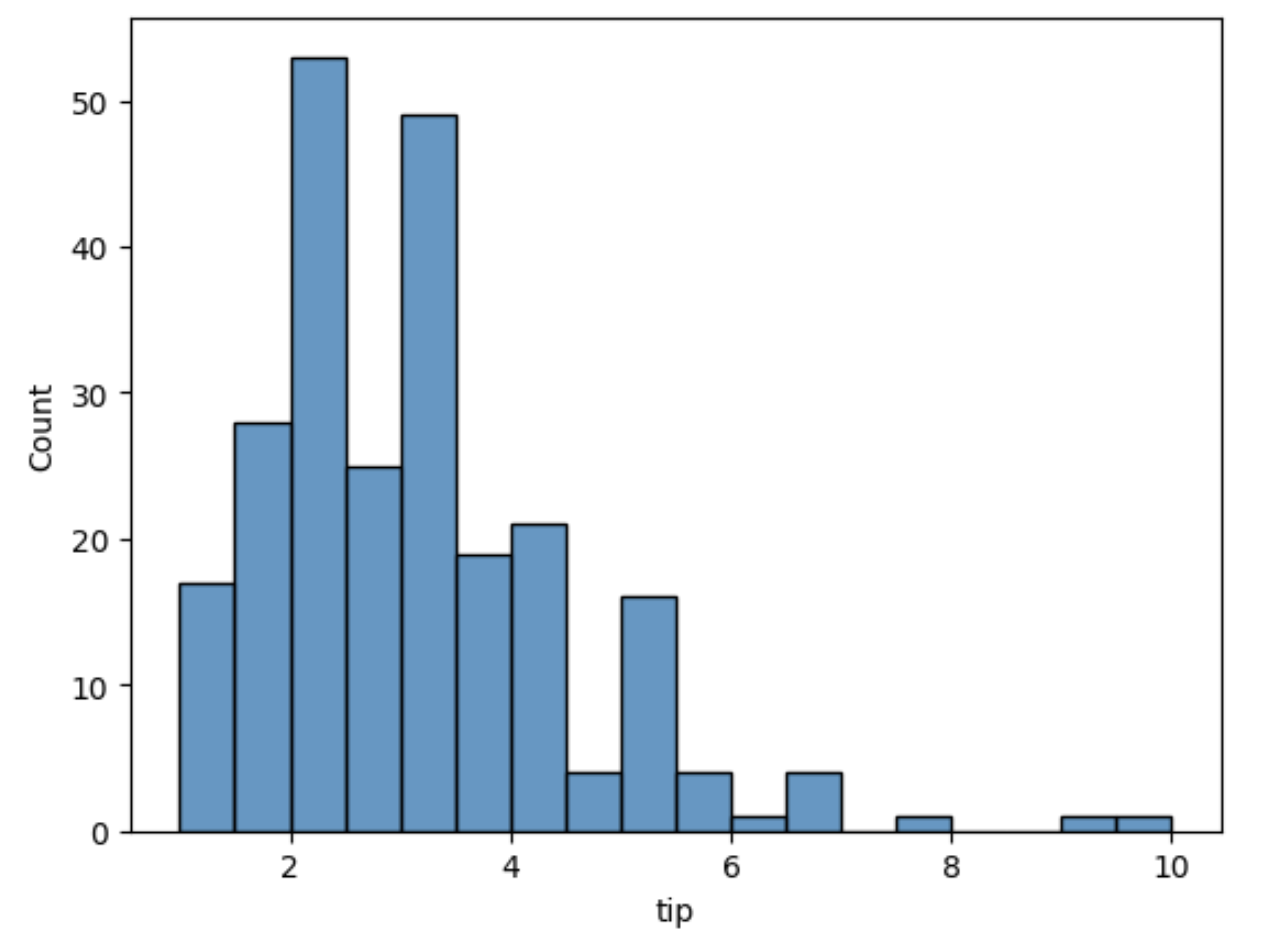
O dados também poderão ser representados com histogramas através da função histplot(), veja exemplo com os dados de gorjeta (tip):
sns.histplot(df["tip"])
Outra opção é utilizar o rugplot() para visualização, veja como ficaria:
# rug
sns.rugplot(data=df, x='tip')
Uma visualização interessante seria unir os 3 layouts em um único gráfico, veja um exemplo de visualização:
# união das 3
sns.displot(data=df,x='total_bill',bins=40, kde=True,rug=True,color='blue',hue='day')
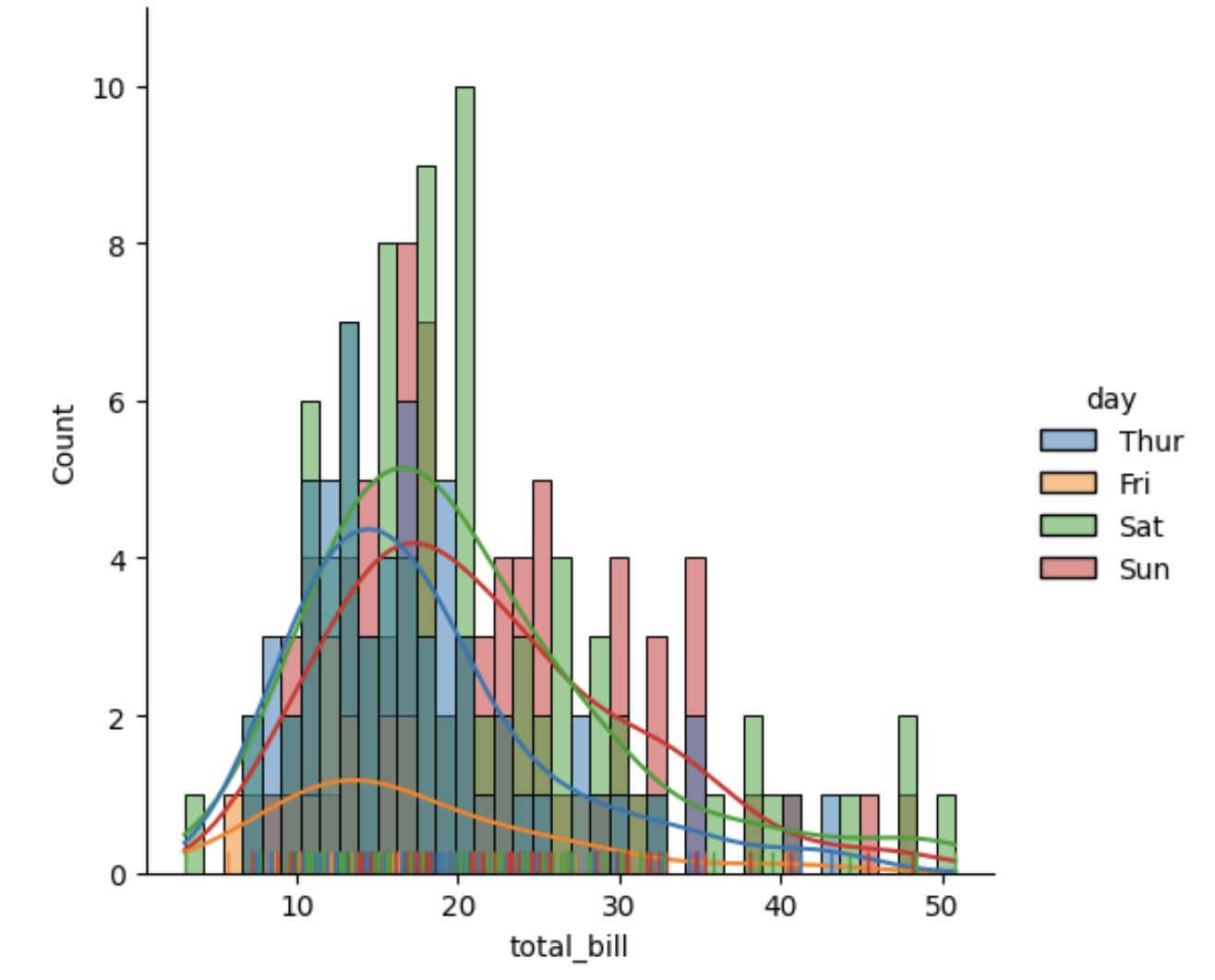
💡 Observe que todos os layouts podem ser customizados e/ou ativados através dos parâmetros bin, kde, rug, color, hue e outros.
Outra função interessante é o jointplot() que permite combinar duas representações distintas, por meio do parâmetro kind, veja o exemplo:
# correlação grafica de duas distribuições
sns.jointplot(x="total_bill",y="tip",data=df,kind='reg')
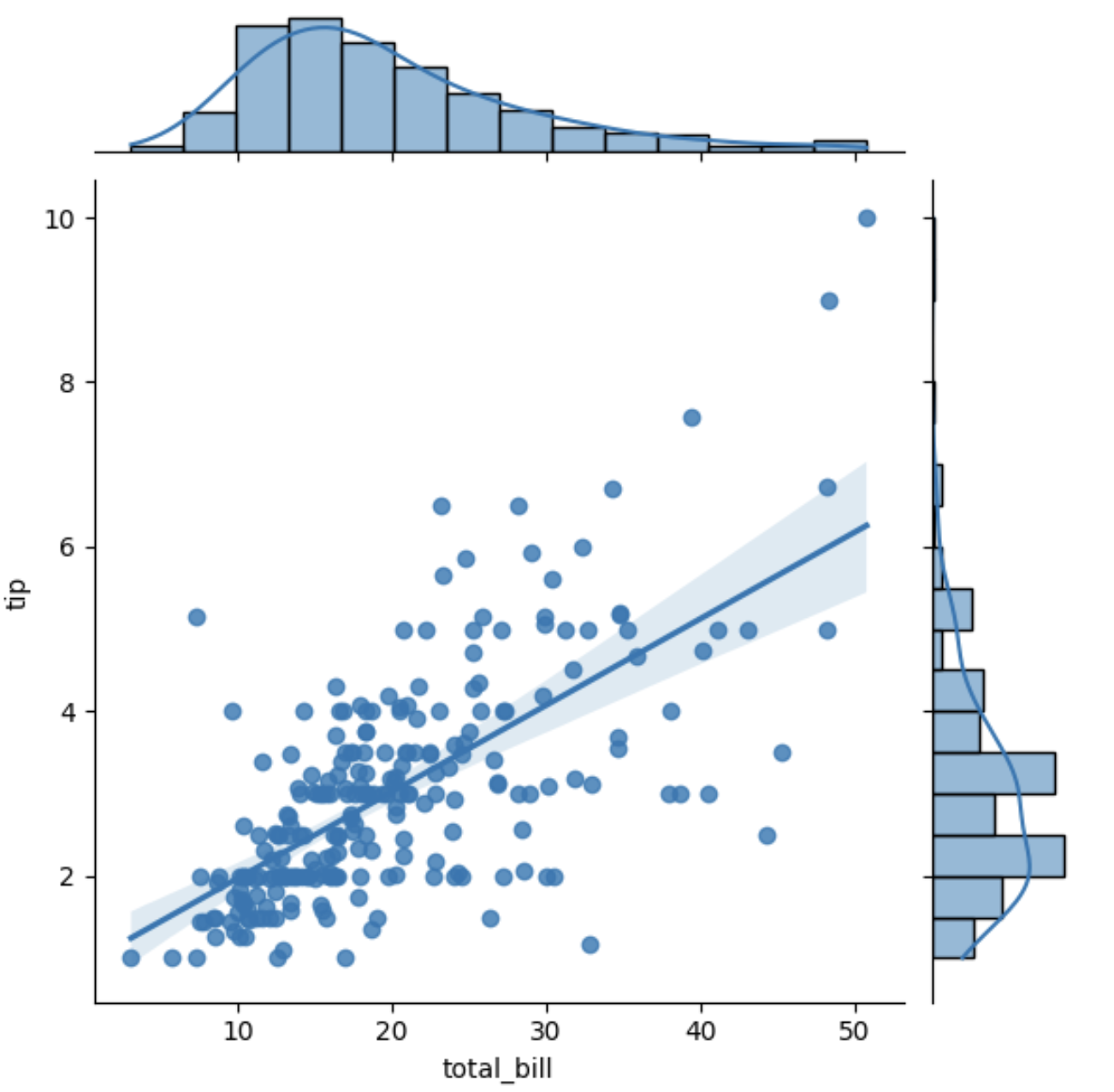
Através do parâmetro kind você pode escolher outras formas de representar a distribuição como scatter, reg, resid, kde e hex. Consulte a documentação para mais detalhes.
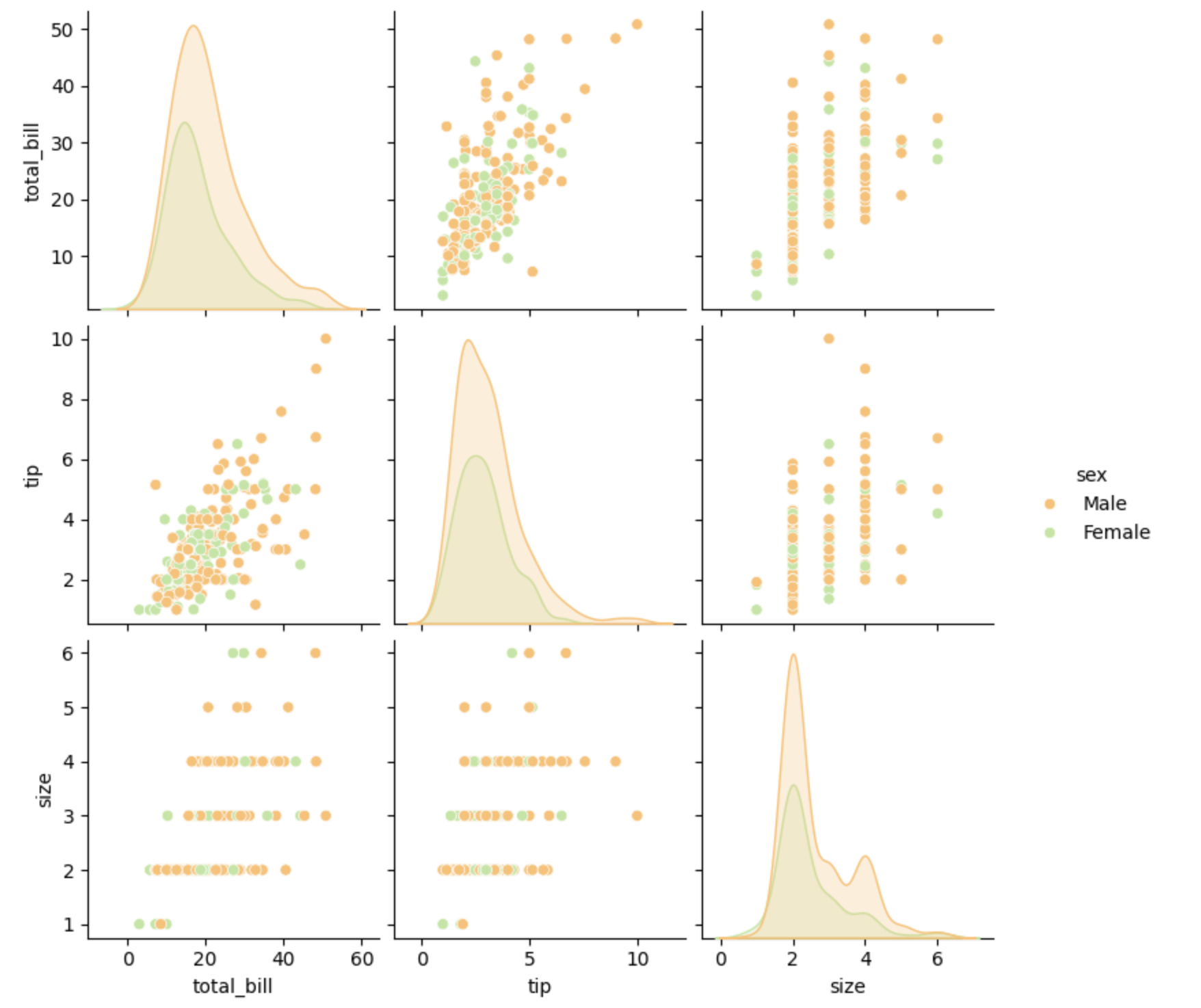
Vamos falar agora do pairplot(), que como o próprio nome sugere exibe as relações entre pares de variáveis em um pandas DataFrame para as colunas numéricas e também exibe uma escala de cores para colunas com variáveis categóricas, veja o exemplo:
# correlação geral dos dados
sns.pairplot(data=df,hue='sex', palette='Spectral')
Até o momento trabalhamos com a representação de dados numéricos, porém temos gráficos específicos para dados categóricos. Vamos falar do barplot() e countplot() que são muito semelhantes, pois ambos permitem que você obtenha dados agregados de um recurso categórico em seus dados. O primeiro é um gráfico que permite agregar os dados categóricos com base em alguma função, por padrão a média. Veja exemplo:
import numpy as np
sns.barplot(data=df, x='sex', y='total_bill', estimator=np.std, hue='day', palette='coolwarm')
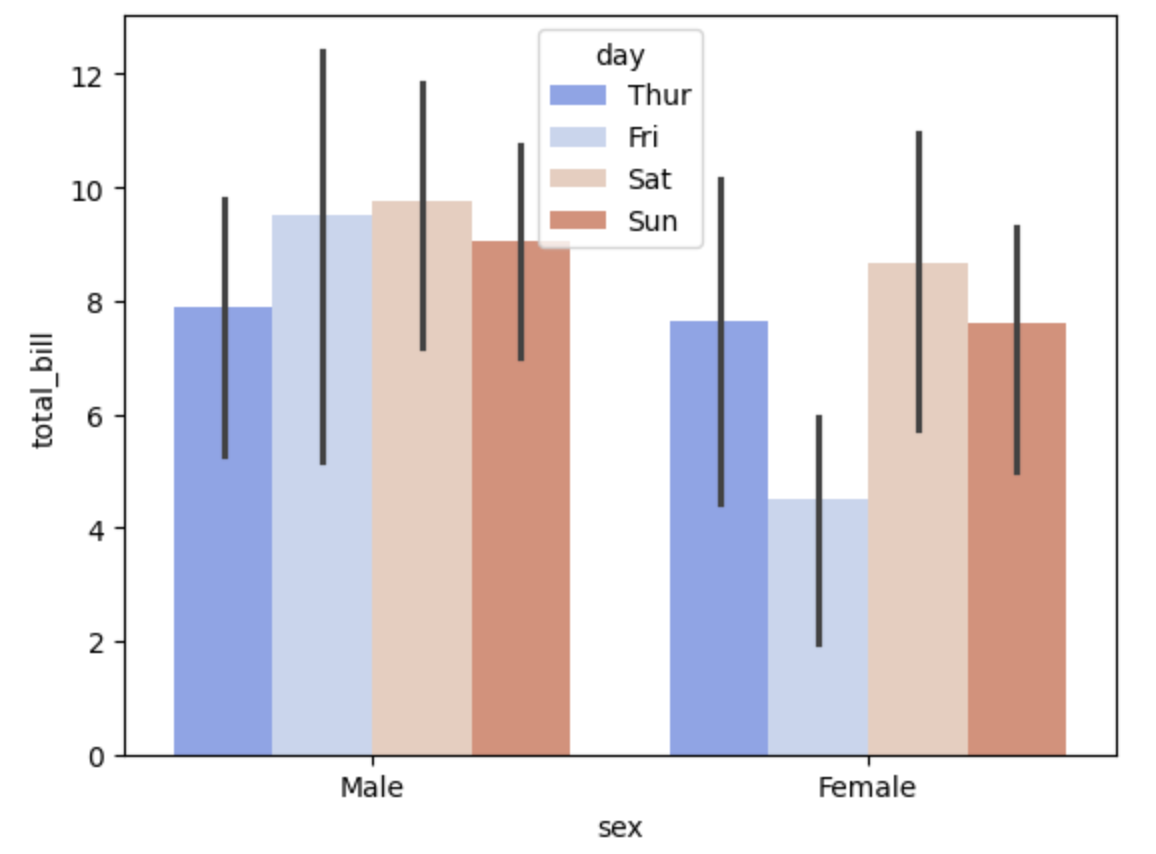
É possível controlar a função de agregação a partir do parâmetro estimado.
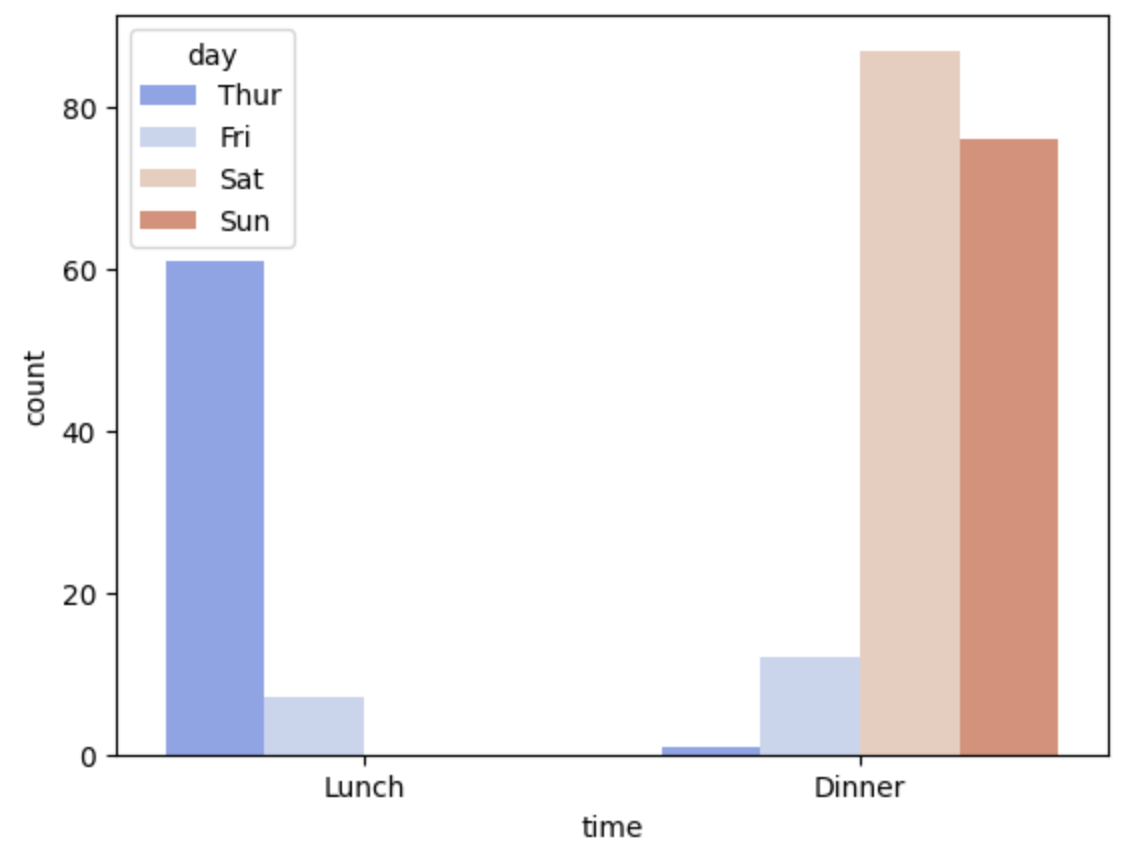
O countplot() é essencialmente o mesmo que o barplot(), exceto que o estimador está explicitamente contando o número de ocorrências. É por isso que só passamos o valor x.
# dados categoricos
# sns.countplot(data=df, x='day')
# sns.countplot(data=df, x='sex')
sns.countplot(data=df, x='time',hue='day', palette='coolwarm')
Outra forma de apresentar os dados é através do boxplot() e violinplot() que mostram a distribuição dos dados categóricos. Esses gráficos mostram a distribuição de dados quantitativos de uma maneira que facilita as comparações entre variáveis ou entre os níveis de uma variável categórica.
O boxplot() mostra os quartis do conjunto de dados enquanto as linhas (whiskers) se estendem para mostrar o restante da distribuição, exceto os pontos que são determinados como outliers usando um método que é uma função da faixa inter-quartil.
sns.boxplot(x="day", y="total_bill", hue="smoker",data=df,palette="coolwarm")

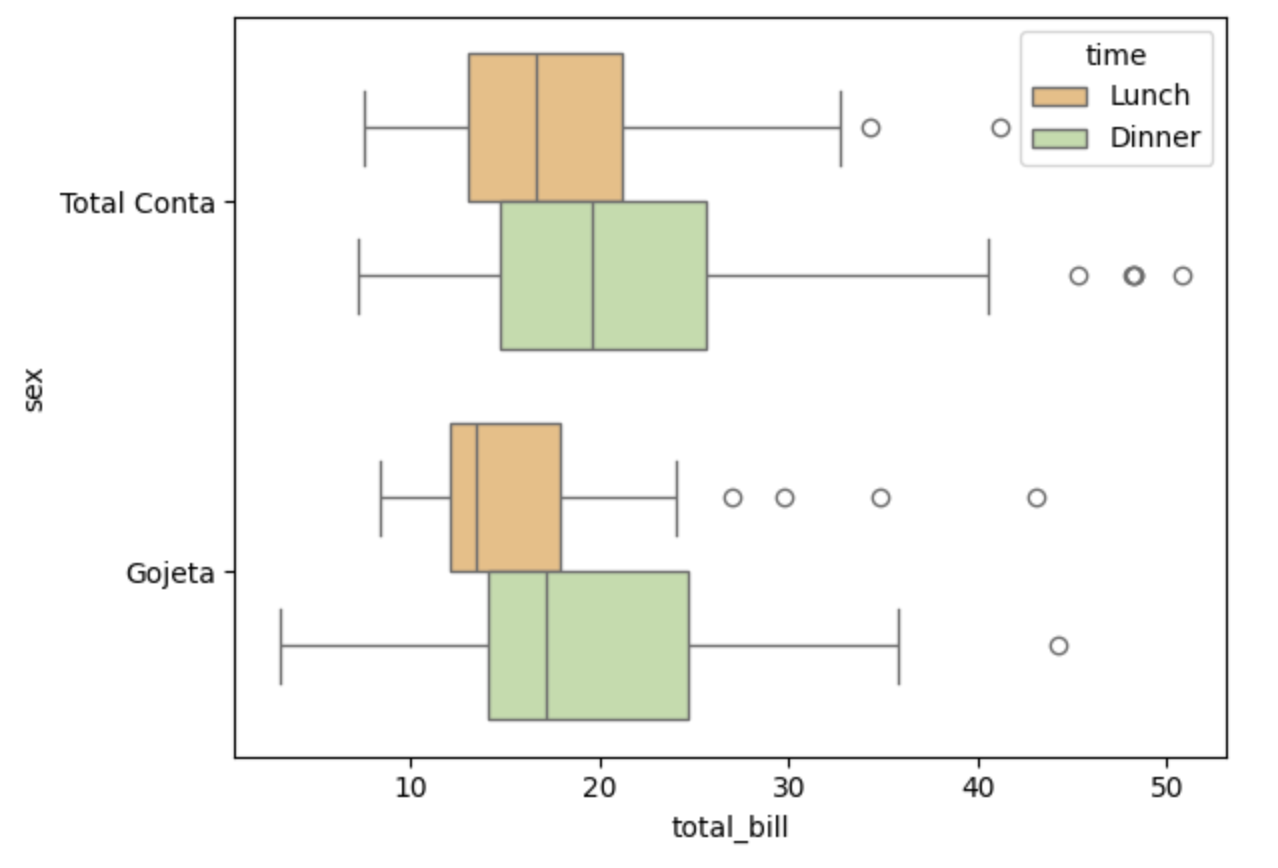
É ainda possivel customizar os rótulos, semelhante ao que vimos no estudo com Matplotlib, veja um exemplo:
import matplotlib.pyplot as plt
fig, axes = plt.subplots()
axes = sns.boxplot(data=df, x='total_bill', y='sex', hue='time', orient='h', palette='Spectral')
axes.set_yticklabels(['Total Conta','Gojeta','Tamanho'])
fig.show()
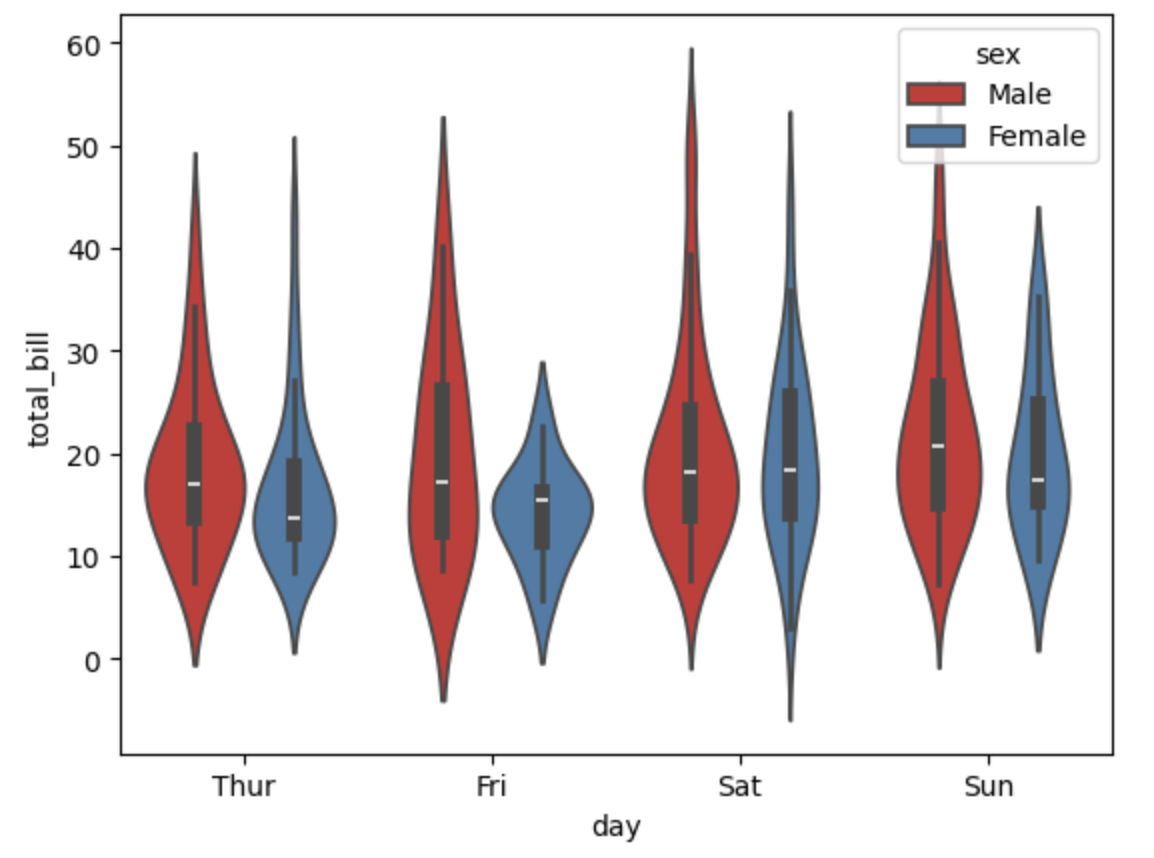
Outro gráfico interessante é o violinplot(), ele mostra a distribuição de dados quantitativos em vários níveis de uma, ou mais, variáveis categóricas, para que essas distribuições possam ser comparadas. Ao contrário do boxplot, no qual todos os componentes do gráfico correspondem aos pontos de dados reais, o gráfico de violino apresenta uma estimativa da densidade do núcleo da distribuição correspondente. Veja exemplo:
sns.violinplot(x="day", y="total_bill",data=df,hue='sex',palette='Set1')
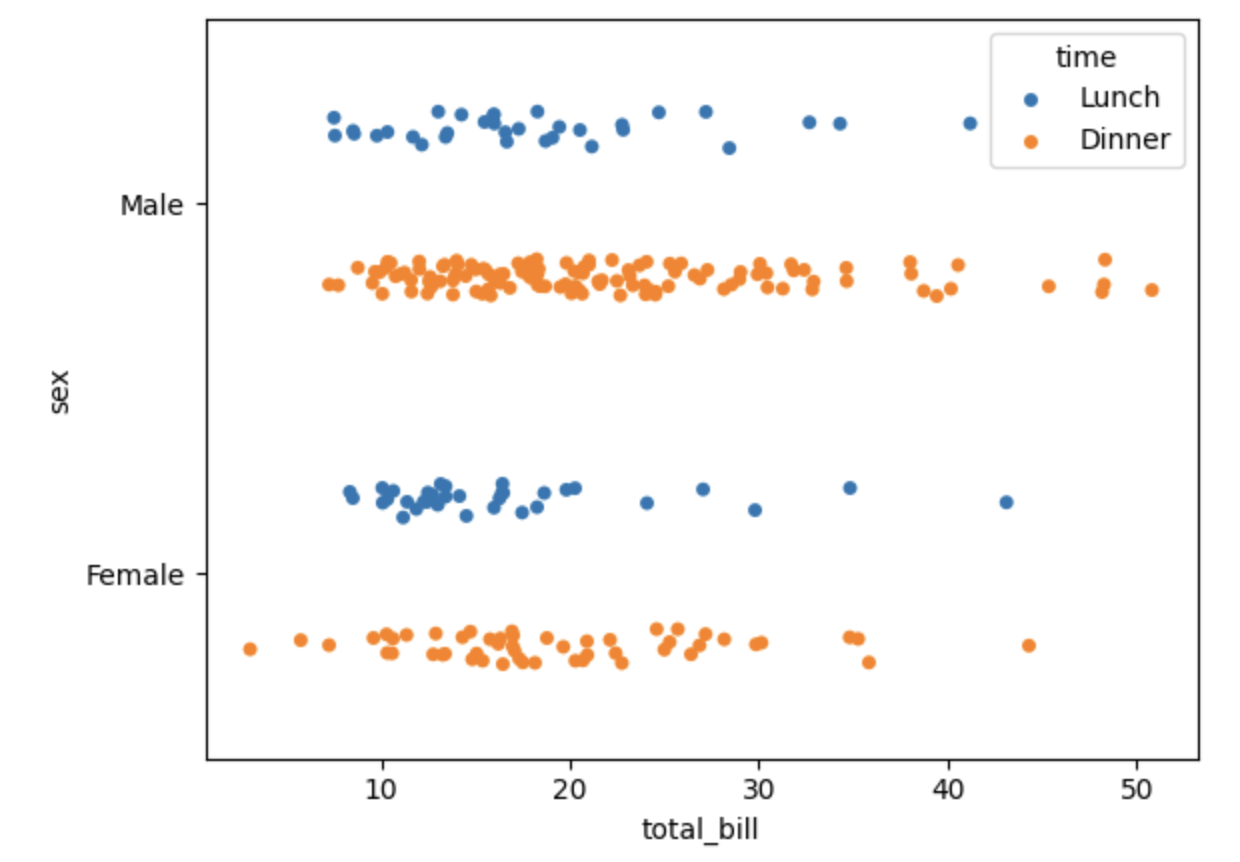
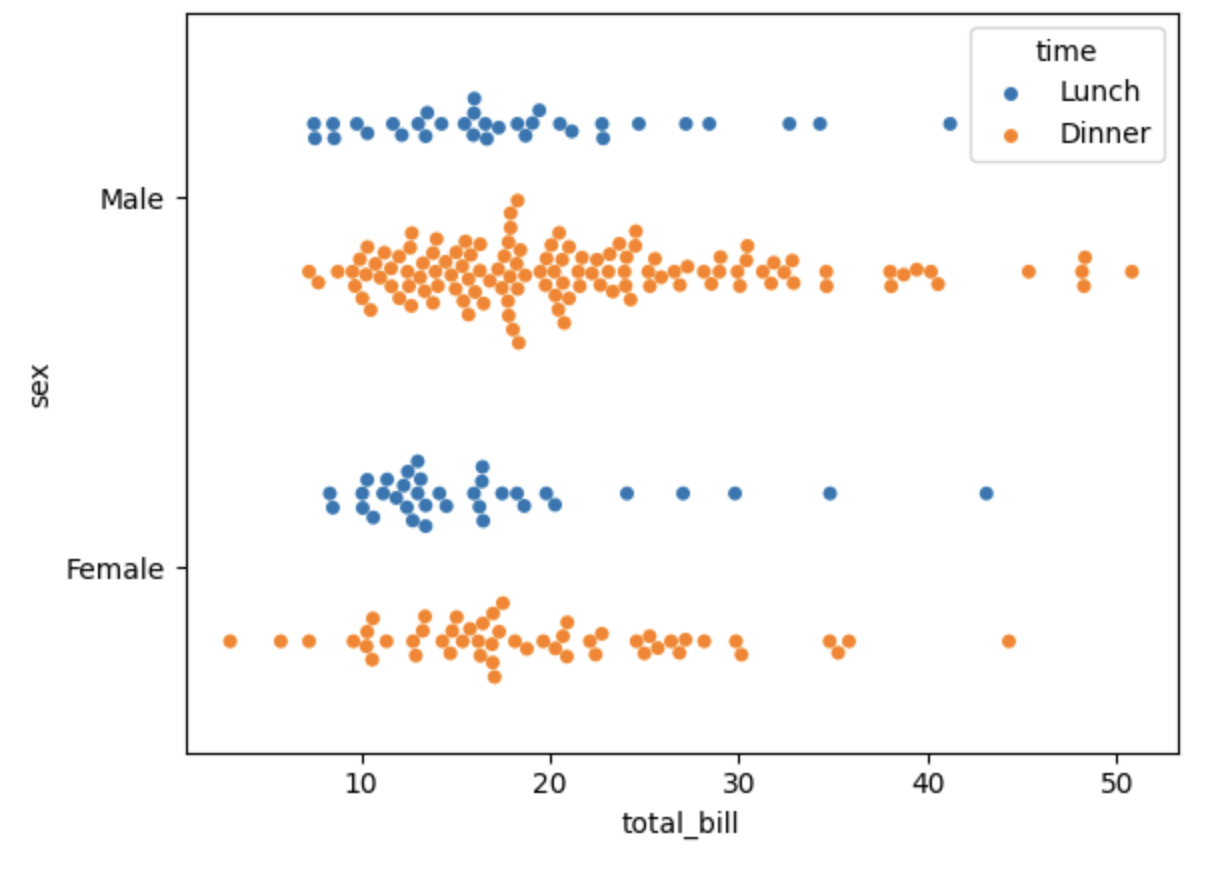
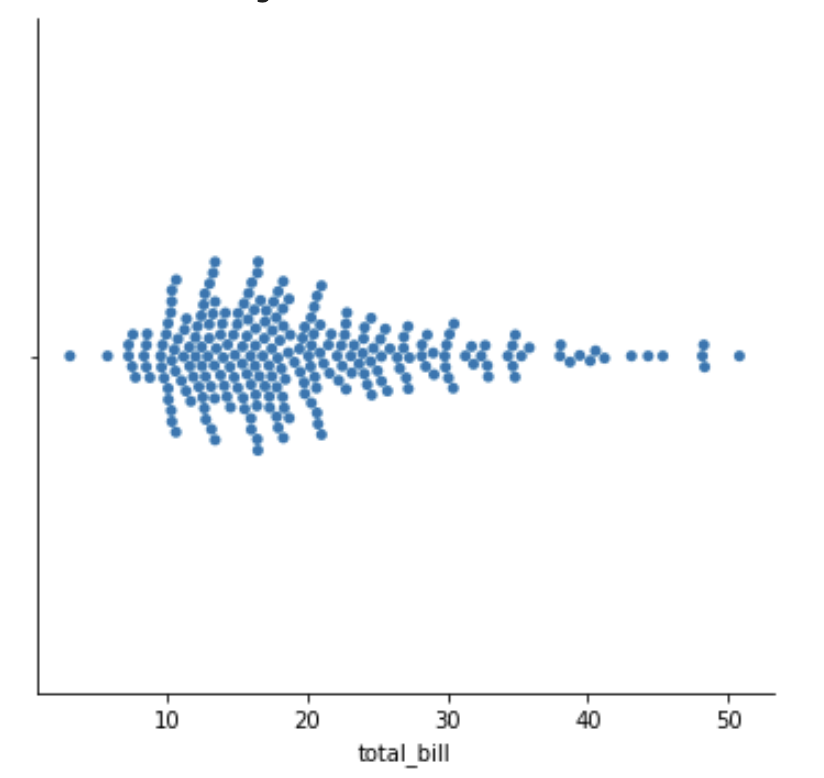
É importante conhecer o stripplot() e swarmplot(), onde o strippplot() desenhará um gráfico de dispersão separado por uma variável categórica e o swarmplot(), de forma semelhante, porém com ajuste dos pontos ao longo do eixo categórico, para que não se sobreponham. Fornece uma boa representação da distribuição dos valores, embora não seja escalável para um grande número de observações, tanto capacidade de apresentação quanto a poder computacional. Veja um exemplo dessas funções abaixo:
sns.stripplot(data=df,x='total_bill',y='sex',hue='time', dodge=True, jitter=True)
sns.swarmplot(data=df,x='total_bill',y='sex',hue='time', dodge=True)
Caso precise de um gráfico categórico mais geral o catplot() certamente é a escolha certa. Pelo parâmetro kind é possível escolher o tipo de gráfico. Veja alguns exemplos:
# plotagem de grafico mais generica que temos na biblioteca
sns.catplot(data=df,x='total_bill', kind='swarm')
sns.catplot(data=df,x='total_bill', kind='box')
sns.catplot(data=df,x='total_bill', kind='strip')


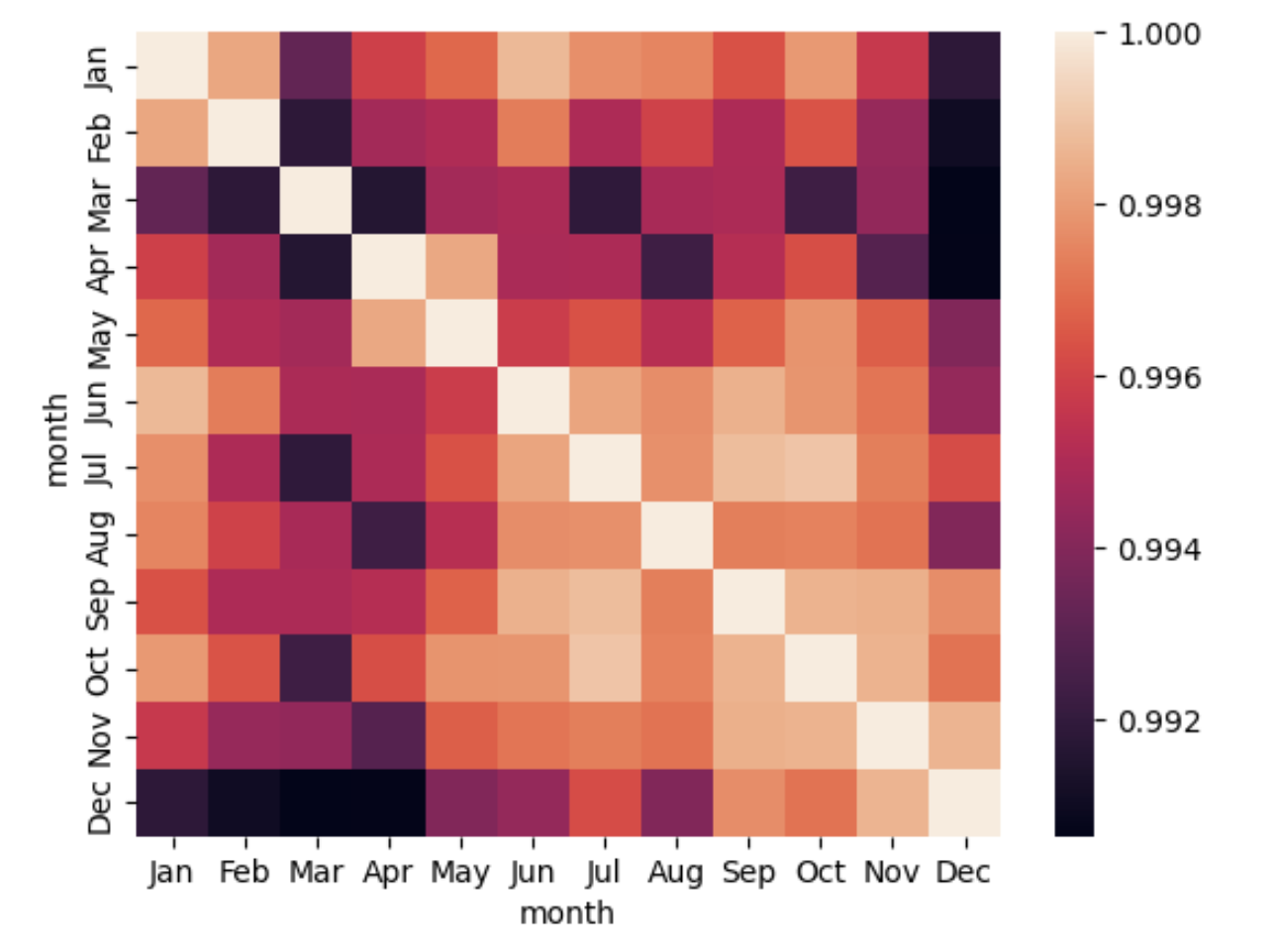
Podemos visualizar os dados de matrizes com o seaborn, uma forma interessante é através do heatmap() que para funcionar corretamente, os dados devem estar em um formato de matriz. Vamos utilizar o Dataset flights nesse exemplo, veja o resultado abaixo:
# Dataset leitura
>> df1 = sns.load_dataset('flights')
>> print(df1.head())
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121
Informações do dataset:
>> df1.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
Convertendo Dataset a partir da função pivot_table() do pandas.
>> df1 = df1.pivot_table(values='passengers', columns='month', index='year')
>> print(df1)
month Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
year
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432
Dessa forma um gráfico da matriz de correlação da quantidade de passageiros mês a mês pode ser visto com a função heatmap() e a função corr(), veja exemplo abaixo:
sns.heatmap(df1.corr())
Vamos fazer o mesmo para Dataframe Tips, veja resultado:
>> df = sns.load_dataset('tips') # Atenção - Data set da propria bibliotecacorr_tips = df.corr()
>> print(df.head())
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
>> corr_tips = df.corr()
>> print(corr_tips)
total_bill tip size
total_bill 1.000000 0.675734 0.598315
tip 0.675734 1.000000 0.489299
size 0.598315 0.489299 1.000000
sns.heatmap(corr_tips, annot=True, square=True, cmap='Spectral')

Temos uma apresentação gráfica da correlação de cada uma das features.
Muito ainda pode ser estudado sobre as bibliotecas para Ciência de Dados, espero que tenham gostado do conteúdo e parabéns por ter chegado até final. Espero vocês nos próximos posts. Até lá =D.